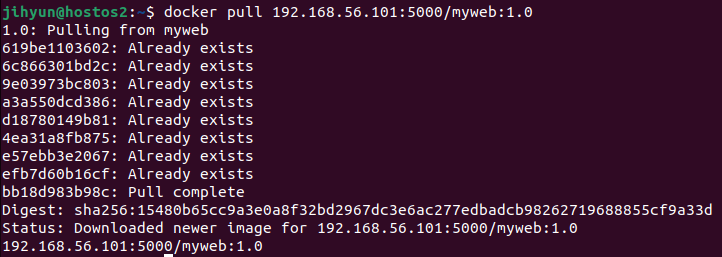
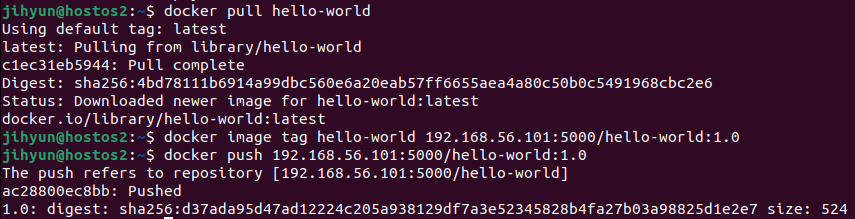
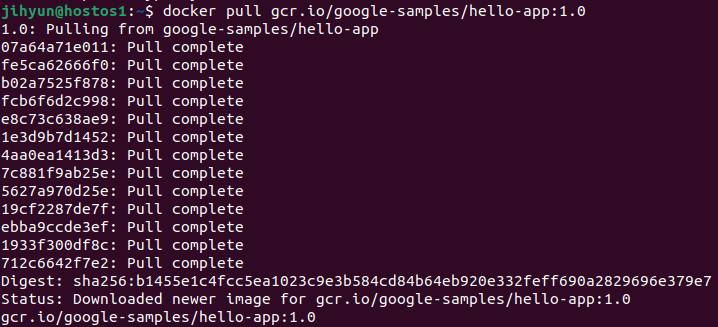
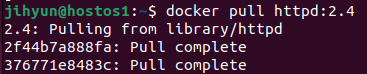
1) SRP (Single Reponsibility Principle) : 단일 책임 원칙
→ 한 클래스는 단 하나의 책임을 가져야 하고, 클래스가 변경되어야 하는 이유는 단 하나의 이유여야 한다.
public class User {
private String username;
private String password;
public User(String username, String password) {
this.username = username;
this.password = password;
}
public boolean isValid() {
// 유효성 검사
return true;
}
public void save() {
// 데이터 저장
}
}
위 클래스는 사용자 정보를 나타내는 클래스이고, 유효성 검사와 데이터 저장은 사용자 정보와 직접적인 연관이 없는 작업이므로 단일 책임 원칙에 어긋난다. → 클래스를 더 작은 단위로 분리하여 단일 책임을 부여하는 것이 바람직하다.
public class User {
private String username;
private String password;
public User(String username, String password) {
this.username = username;
this.password = password;
}
}
public class UserValidator {
public boolean isValid(User user) {
// 유효성 검사
return true;
}
}
public class UserDAO {
public void save(User user) {
// 데이터 저장
}
}
위와 같이 클래스를 분리하여 User 클래스는 사용자 정보만 관리하고, 유효성 검사와 데이터 저장은 각각 다른 클래스에서 담당한다.
→ 코드의 유지보수성이 증가하고, 다른 기능을 추가하거나 변경할 때 영향을 최소화할 수 있다.
2) OCP (Open-Closed Principle) : 개방-폐쇄 원칙
→ 기존 코드를 변경하지 않으면서 기능을 확장할 수 있도록 설계해야 한다.
public interface Shape {
double calculateArea();
}
public class Circle implements Shape {
private double radius;
public Circle(double radius) {
this.radius = radius;
}
public double calculateArea() {
return Math.PI * radius * radius;
}
}
public class Rectangle implements Shape {
private double width;
private double height;
public Rectangle(double width, double height) {
this.width = width;
this.height = height;
}
public double calculateArea() {
return width * height;
}
}
public class AreaCalculator {
public double calculateArea(Shape[] shapes) {
double totalArea = 0;
for (Shape shape : shapes) {
totalArea += shape.calculateArea();
}
return totalArea;
}
}
shape 인터페이스는 다양한 도형의 면적을 계산하기 위한 공통 기능을 정의하고, Circle과 Rectangle 클래스는 각각 원과 사각형의 면적을 계산하는 구체적인 기능을 구현한다.
AreaCalculator 클래스는 입력받은 여러 도형의 면적을 모두 더해 총 면적을 계산하는 역할을 하고, 이때 shape 인터페이스를 구현한 어떤 도형 클래스도 입력받을 수 있다. 이로 인해 새로운 도형 클래스가 추가되더라도 AreaCalculator 클래스는 수정할 필요 없이 기존의 동작을 그대로 유지할 수 있다.
→ 서브 타입은 언제나 기반 타입으로 교체할 수 있어야 한다. 자식의 일은 부모의 일보다 작거나 같아야 한다.
즉, 자식클래스가 부모클래스의 인스턴스 대신 사용될 때 언제나 정상적으로 작동해야 한다.
public class PrintPositiveNum {
private int num;
public PrintPositiveNum(int num){
this.num = num;
}
public getNum(){
if(this.num <= 0){
throw new RuntimeException("0 이하는 출력 불가능!!!");
}
return this.num;
}
}
public class PrintNum extends PrintPositiveNum {
@Override
public getNum(){
return this.num;
}
}
public class Client{
public static void main(String[] args){
PrintPositiveNum obj = new PrintPositiveNum(1);
//PrintPositiveNum obj = new PrintNum(-1); // 이 경우 위반
obj.getNum();
}
}
위 코드에서 PrintPositiveNum은 부모클래스로 양수만 화면에 출력 가능, 자식클래스인 PrintNum은 모든 범위의 숫자 출력 가능
Client 클래스에서 양수를 주는 경우 어떤 타입이 들어와도 실행가능하지만, 음수나 0의 경우 클라이언트측 코드를 수정해야만 함
부모가 수행가능한 범위 내에서만 오버라이딩을 해야 클라이언트측 코드를 고칠 필요가 없어진다는 것이 리스코프 치환 원칙의 핵심
4) ISP (Interface Segregation Principle) : 인터페이스 분리 원칙
→ 인터페이스는 클라이언트에 특화되어야 하고, 클라이언트가 사용하지 않는 메서드는 포함하지 않아야 한다.
public interface Shape {
double calculateArea();
double calculateVolume();
}
public class Rectangle implements Shape {
private double width;
private double height;
public double calculateArea() {
return width * height;
}
public double calculateVolume() {
throw new UnsupportedOperationException();
}
}
public class Cube implements Shape {
private double width;
private double height;
private double depth;
public double calculateArea() {
return 2 * (width * height + width * depth + height * depth);
}
public double calculateVolume() {
return width * height * depth;
}
}
Shape 인터페이스는 도형의 면적과 부피를 계산하는 두 가지 메서드를 정의하는데, Rectangle 클래스는 면적만 가능하고 부피를 계산할 수 없기 때문에 ISP를 위반한다. 즉, 클라이언트는 Shape 인터페이스를 구현한 모든 클래스에서 부피 계산 메서드를 사용해야 하기 때문에 불필요한 의존성이 발생된다.
public interface Area {
double calculateArea();
}
public interface Volume {
double calculateVolume();
}
public class Rectangle implements Area {
private double width;
private double height;
public double calculateArea() {
return width * height;
}
}
public class Cube implements Area, Volume {
private double width;
private double height;
private double depth;
public double calculateArea() {
return 2 * (width * height + width * depth + height * depth);
}
public double calculateVolume() {
return width * height * depth;
}
}
위와 같이 클라이언트가 자신이 사용하지 않는 메서드에 의존하지 않도록 인터페이스를 작게 분리해야 한다.
→ 상위 수준 모듈은 하위 수준 모듈에 의존하지 않아야 하고, 추상화는 구체적인 사항에 의존하지 않아야 한다.
① 고차원 모듈은 저차원 모듈에 의존해서는 안 된다.
② 추상화는 세부사항에 의존해서는 안된다.
public class RedLight {
public void turnOn() {
System.out.println("Red Light turned on");
}
}
public class Switch {
private RedLight light;
public Switch() {
this.light = new RedLight();
}
public void flip() {
if (light != null) {
light.turnOn();
}
}
}
위 코드에서 Switch 클래스는 RedLight 클래스를 직접 생성하고 사용하므로 Switch 클래스가 Redlight 클래스에 의존하게 된다.
만약 RedLight 클래스를 BlueLight 클래스로 변경한다면 Switch 클래스도 변경해야 하는 문제가 발생한다.
public interface Light {
void turnOn();
}
public class RedLight implements Light {
@Override
public void turnOn() {
System.out.println("Red Light turned on");
}
}
public class Switch {
private Light light;
public Switch(Light light) {
this.light= light;
}
public void flip() {
if (light!= null) {
light.turnOn();
}
}
}
위 코드에서 Switch 클래스는 Light 인터페이스를 통해 RedLight 클래스와 의존 관계를 맺는다. 이렇게 함으로써 RedLight 클래스에 변경이 생긴다고 해도 Switch 클래스는 영향을 받지 않는다.
FROM node:20-alpine3.17 // 어떤 os와 프레임워크 위에서 돌릴지
RUN apk add --no-cache tini curl // 알파인 리눅스이므로 apk로 구동
WORKDIR /app // /app이라는 경로 생성 후 cd /app 실행
COPY app.js . // Dockerfile과 같은 경로의 app.js를 현재경로에 복사
EXPOSE 5678 // 포트바인딩 시 컨테이너 측의 노출포트가 5678
ENTRYPOINT ["/sbin/tini", "--"] // 내부적으로 app.js를 실행해주는 명령어
CMD ["node", "app.js"] // (ENTRYPOINT와 CMD)
위 명령어로 이미지를 생성한다.
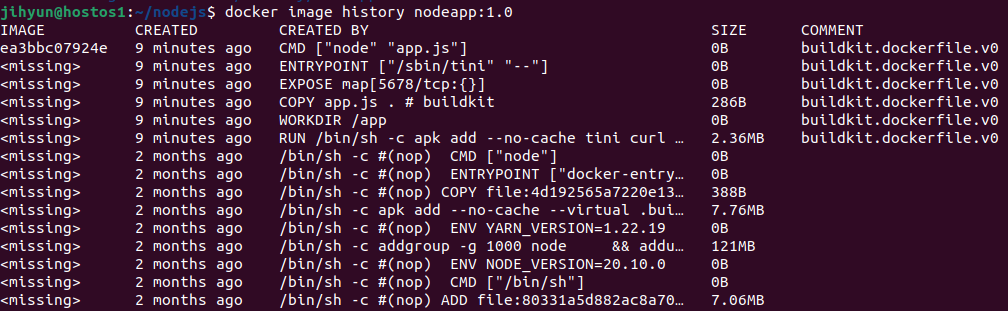
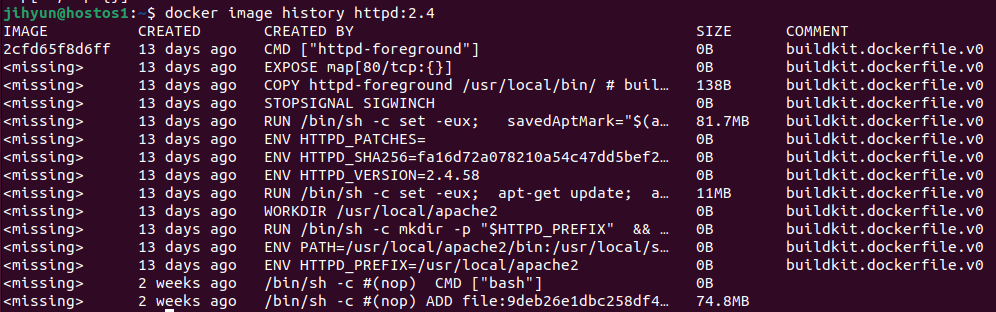
위와 같이 history 명령어로 nodeapp의 내용을 확인해볼 수 있다.
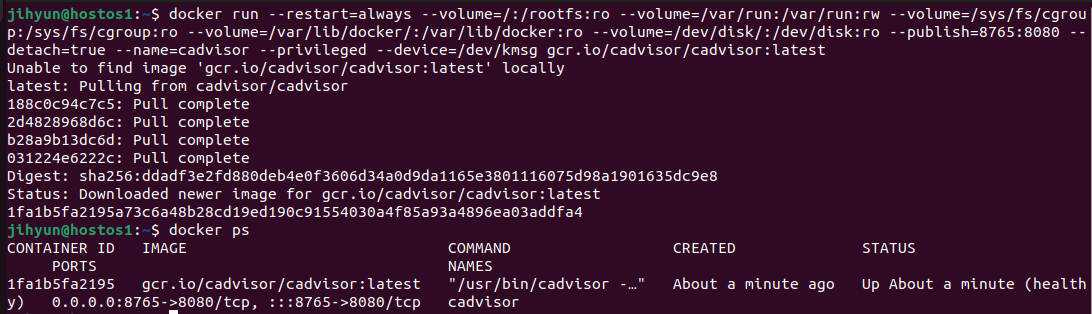
run 명령어로 컨테이너를 실행하고, 조회해보면 위와 같이 잘 띄워진 것을 확인할 수 있다.
-h 옵션은 hostname을 nodeapp으로 구성하겠다는 의미이다. 해당 태그를 주지 않으면 컨테이너 아이디가 hostname으로 부여된다.
※ 세부옵션
--env
컨테이너의 환경변수 지정
-d --detach=true
백그라운드 실행모드 활성화, 컨테이너 아이디 등록
-t
TTY 할당 (bash창 열어주기)
-i --interactive
대화식 모드 열기 (컨테이너 내부에 명령어 주고받기)
--name
실행되는 컨테이너에 이름 부여 (미지정 시 랜덤한 2단어 조합명으로 부여)
--rm
컨테이너 종료 시 자동으로 컨테이너 제거 (stop 시 삭제)
--restart
컨테이너 종료 시 적ㅈ용할 재시작 정책 지정 (no, on-failure, on-failure:n(횟수), always)
-v --volume=호스트경로:컨테이너경로
볼륨설정 (볼륨마운트)
-h
컨테이너의 호스트명 지정 (미지정 시 컨테이너 아이디를 호스트명으로 등록)
-p 호스트포트:컨테이너포트 --publish
호스트 포트와 컨테이너 포트를 바인딩
-P --publish-all=true|false
컨테이너 내부의 EXPOSE 포트를 랜덤포트와 바인딩
--workdir -w
컨테이너 내부의 작업 경로 (디렉터리)
docker top 명령어를 이용하여 컨테이너에서 현재 실행 중인 프로세스의 상태를 볼 수 있다.
docker port 명령어를 이용하여 포트정보를 알 수 있고, IPv4와 IPv6에 대한 정보가 모두 나온다.
위 명령어를 이용해 docker-proxy라는 대리포트 값을 조회할 수 있다.
위에서 얻은 프록시 값으로 위 명령어 입력 시 해당 포트바인딩 명령어의 정보가 저장된 위치가 나온다.
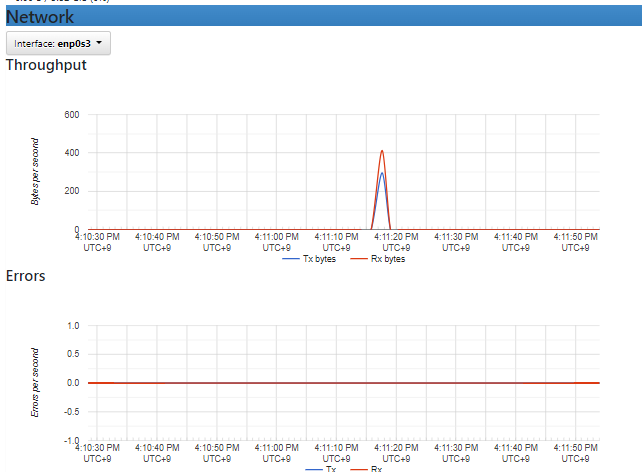
docker stats 명령어로 실시간으로 어떻게 자원을 소비하고 있는지 확인할 수 있다.
해당 컨테이너로 curl이나 브라우저 접속을 유도하면 갑자기 사용량이 증가하는 것을 관찰할 수 있다.
컨테이너명을 여러개 적으면 동시에 조회도 가능하며 흐름에 따른 갱신을 보고싶지 않다면 --no-stream 옵션을 추가하면 된다.
6. 모니터링용 이미지 및 컨테이너로 상태 감시
1) cadvisor
→ docker stats로도 상태를 감시할 수 있지만 좀 더 전문적으로 감시할 수 있는 툴
→ 도커허브가 아닌 gcr에 올라와 있기 때문에 아래와 같은 명령어들로 볼륨마운트를 해야만 볼 수 있다.