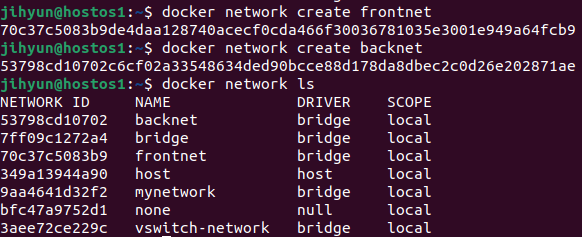
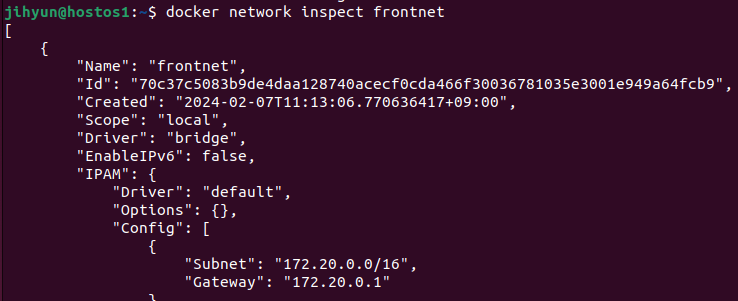
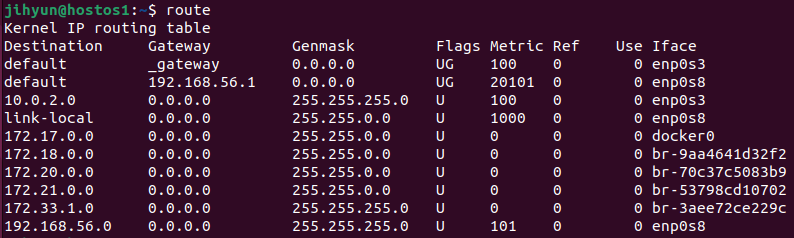
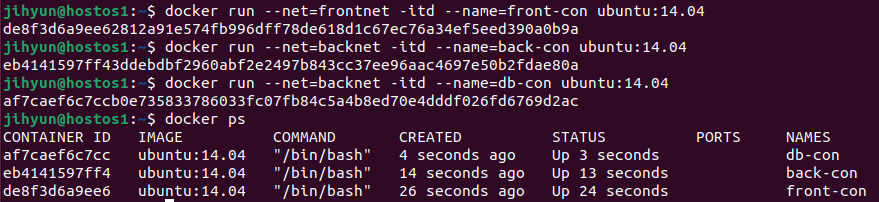
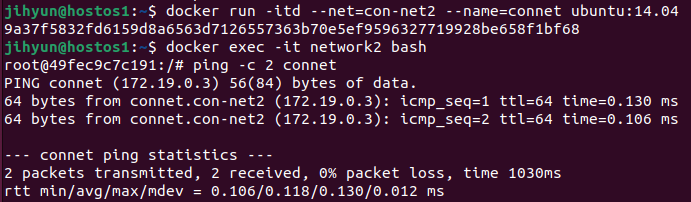
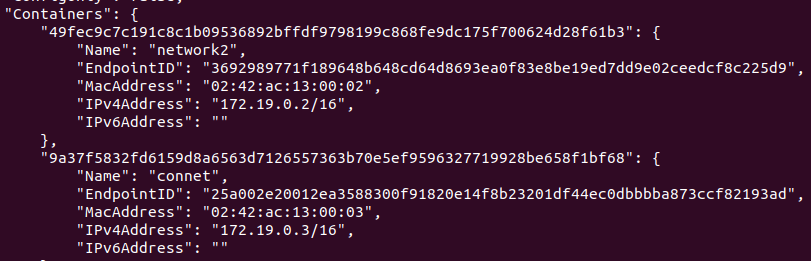
1. 프록시
1) 프록시가 없다면?
- 사용자 요청이 직접 웹서버에 전달 → 서버 부담 증가
- 단일 웹서버 : 장애 발생 시 서비스 가용성에 치명적인 문제
- 다중 웹서버 : hotspot → 한 서버에 트래픽이 몰리는 현상, 사용자 입장에서 레이턴시가 증가하는 문제
2) 프록시
- 사용자의 요청을 대리로 받아 서버들에게 적절히 분배
- 다중 호스트에 트래픽을 분산시킬 수 있는 로드밸런싱 구현이 가능
- html, js, css 등의 정적 파일을 캐싱할 수 있는 캐시서버 구현
- 학교나 사내망에서 특정 사이트 접근을 제어하는 차단 기능 구현
- 무중단 배포를 통한 서비스 경험 향상 및 내구성 증가
- SSL 암호화 적용을 통한 보안 강화 가능
- 프록시 서버 종류
① 포워드 프록시 : 사용자의 존재를 서버에게서 숨김
② 리버스 프록시 : 서버의 존재를 사용자에게서 숨김
3) nginx
- 기본 구성값으로 웹서버 실행 가능, 점유율 높음
- config 파일의 간단한 수정만으로 리버스 프록시 구현 가능
- 쿠버네티스의 인그레스 컨트롤러로 엔진엑스 인그레스 컨트롤러 선택 가능
- API 트래픽 처리를 고급 http 기능으로 사용 가능한 API gateway 구성 가능
- MSA 트래픽 처리를 위한 MicroGateway로 사용 가능
- /etc/nginx 하위에 있는 nginx.conf 파일에 대한 변경을 통해 구성 가능
2. nginx 리버스 프록시
1) nginx 리버스 프록시
- nginx 기본 설정 : 80번 포트
- 기본 분배 방식 : round-robin
- 요청이 더 적게 들어오는 서버에 배정을 늘리는 least_conn 방식 채택 가능
- weight 설정 등을 통해 비중을 다르게 가져갈 수도 있음
2) nignx 리버스 프록시 실습
$ sudo apt update
$ sudo apt-get -y install nginx
$ sudo nginx -v
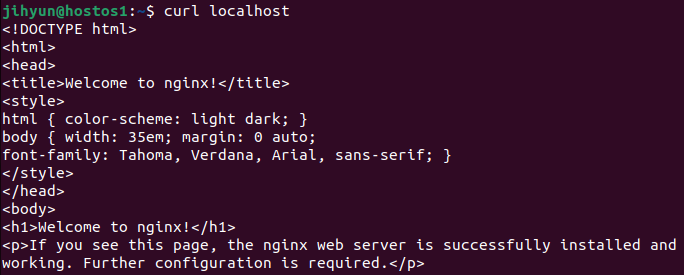
먼저, 위와 같은 명령어로 nginx를 hostos에 설치한 후 진행한다.
nginx는 기본적으로 80번 포트를 사용하기 때문에 포트바인딩이 80번 포트로 되어 있다면 기존에 돌고 있는 컨테이너를 종료시켜줘야 한다.
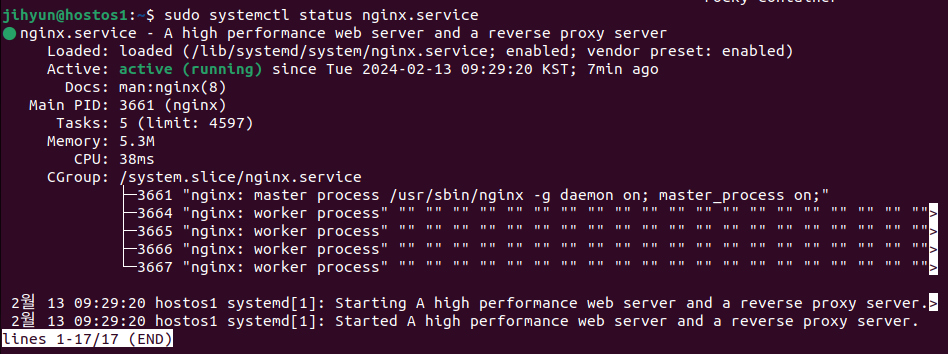
위 명령어로 서비스가 잘 가동되고 있는 것을 확인할 수 있다.

위와 같이 nginx:master로 80번 포트가 잡힌 것을 볼 수 있다.

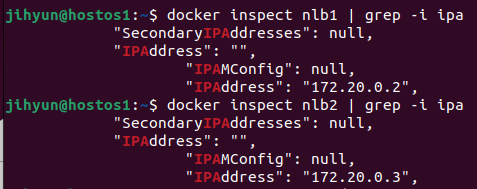
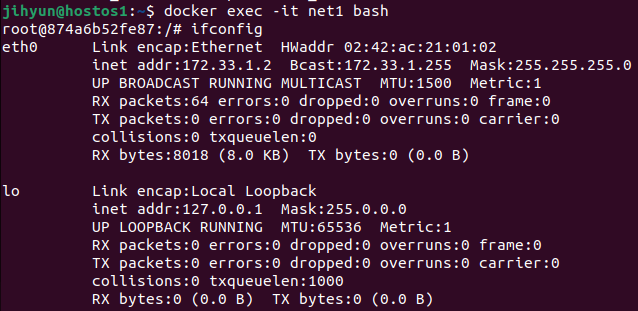
먼저, myweb:1.1 컨테이너의 노출 포트번호를 확인해보면 80번 포트로 되어 있는 것을 확인할 수 있다.

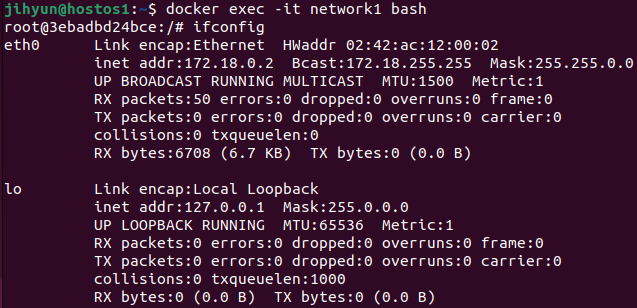
위와 같이 3개의 컨테이너를 띄워준다.
<h1>포트번호 : xxxxx, 컨테이너명 : mywebx</h1>
nginx 내부의 index.html 파일 내용을 바꿔주기 위해 위와 같이 수정한 후
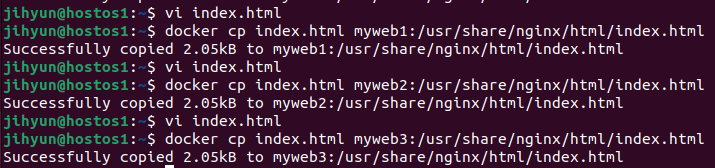
위 명령어를 이용해 index.html을 각각 컨테이너명에 복사해준다.



위와 같이 세 개의 컨테이너가 잘 띄워진 것을 확인할 수 있다.
☆ 사용자 입장에서는 서버 3개의 주소로 직접 접속하지 않아도 nginx 서버 접속 시 번갈하가며 분배되도록 host nginx의 reverse proxy 설정을 해야 한다. → 프록시의 역할
reverse proxy 설정은 /etc/nginx/nginx.conf 파일을 통해 할 수 있다. (해당 파일을 백업해둔 후 진행하자..)

위와 같이 nignx.conf 파일을 수정해준다.
80번 포트로 접속 시 localhost:11111, 22222, 33333을 번갈아가면서 배정하라는 의미이다.

위와 같이 nginx 서버를 restart해준 후 active 상태를 확인해준다.



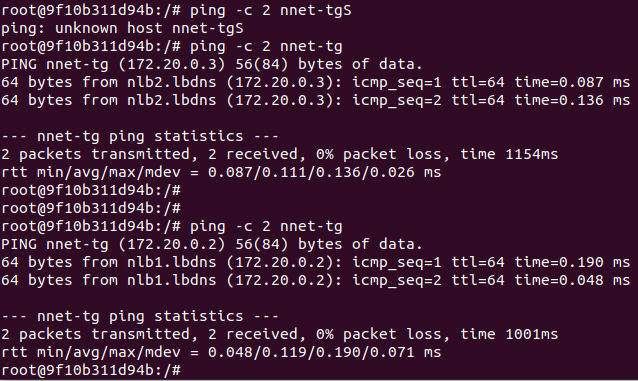
이제 그냥 localhost(80번포트)로 접속해도 위와 같이 번갈아가면서 배정되는 것을 확인할 수 있다.

호스트에 설치되어 있던 리버스 프록시를 컨테이너화 시키기 위해 먼저 서버 중단 후 현재 리버스 프록시 설정된 파일을 백업해둔다.
해당 백업파일을 이용하여 새로운 컨테이너의 nginx.conf 파일을 갱신해주면 리버스 프록시를 수행할 수 있다.

위와 같이 nginx를 제거하면 리버스 프록시는 사라지지만 개별 컨테이너는 삭제되지 않은 상태이다.

위와 같이 nginx 컨테이너를 하나 더 띄워주었다.
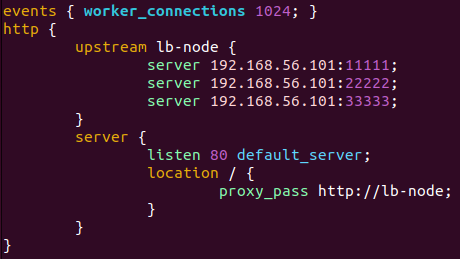
컨테이너 입장에서는 127.0.0.1이 localhost이므로 nginx.conf 파일의 server 부분을 내부 IP 주소(192.168.56.101)로 수정해주어야 한다.

해당 컨테이너의 nginx.conf 파일을 위와 같이 갱신해준다.
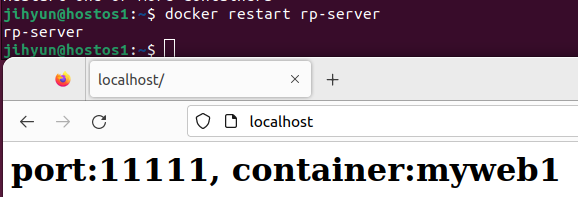
해당 컨테이너를 재시작한 후 접속해보면 위와 같이 프록시가 잘 설정된 것을 확인할 수 있다.
events { worker_connections 1024; }
http {
upstream lb-node {
server hostip:11111 weight=80;
server hostip:22222 weight=10;
server hostip:33333 weight=10;
}
server {
listen 80 default_server;
location / {
proxy_pass http://lb-node;
}
}
}
위와 같이 weight를 주면 가중치에 따라 각 서버가 받는 하중을 다르게 가져가도록 설정할 수도 있다.
3. HAproxy
1) HAproxy
- 하드웨어 기반의 L4/L7 스위치를 대체하기 위한 프록시 솔루션
- TCP 및 HTTP 기반 애플리케이션을 위한 고가용성, 로드밸런싱 및 프록시 기능 제공
- 주요 기능 : SSL 지원, 로드밸런싱, 액티브 헬스체크, keep alived 등
- L4 스위치 대체 기능 : IP를 통한 트래픽 전달 수행, 요청에 대한 처리는 round-robin 방식을 기본으로 함
- L7 스위치 대체 기능 : HTTP 기반의 URI를 통한 트래픽 전달 가능 , 동일한 도메인의 하위에 존재하는 여러 WAS 사용 가능
2) HAproxy를 활용한 컨테이너 L7 스위치 프록시 실습 : HTTP 기반
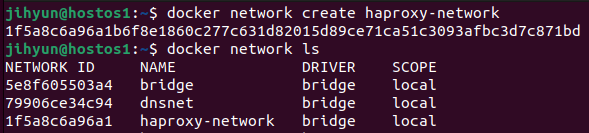

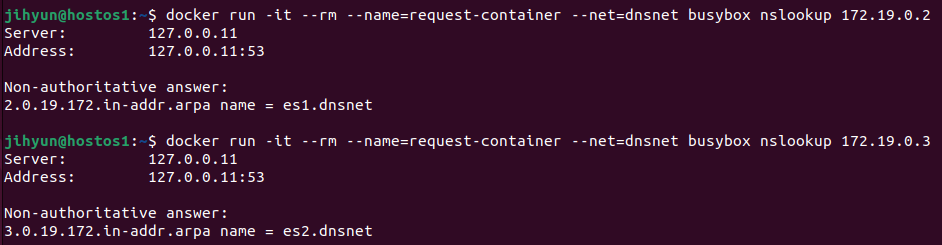
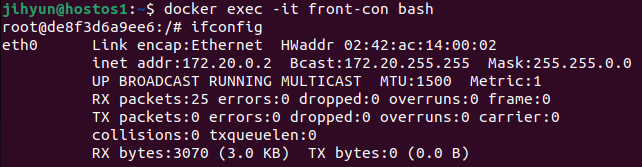
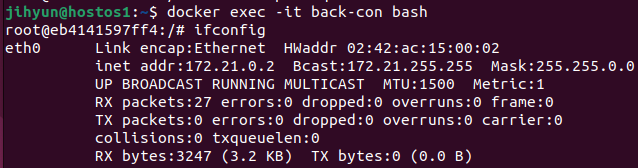
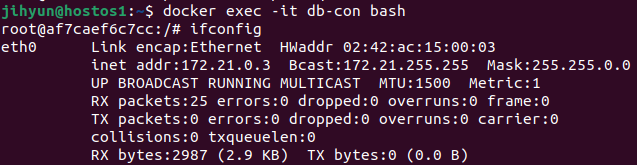
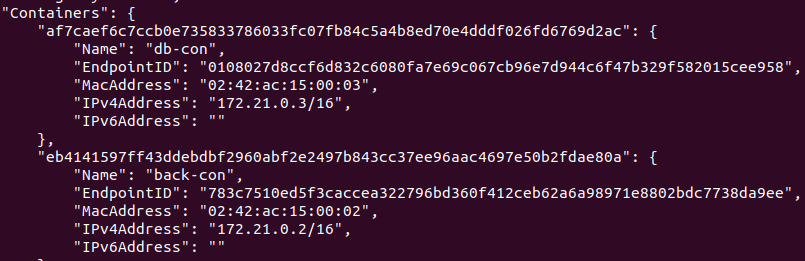
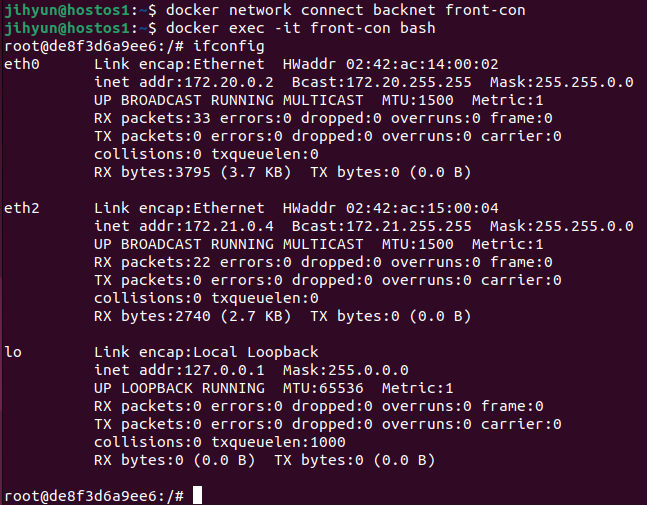
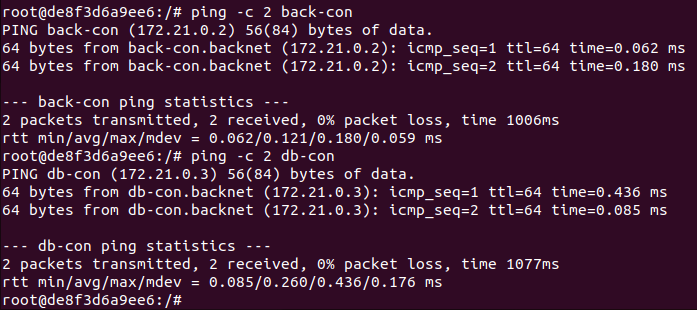
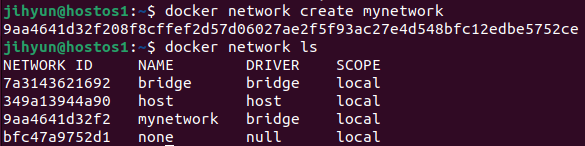
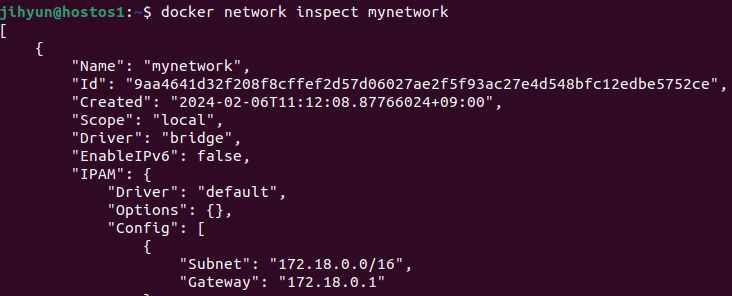
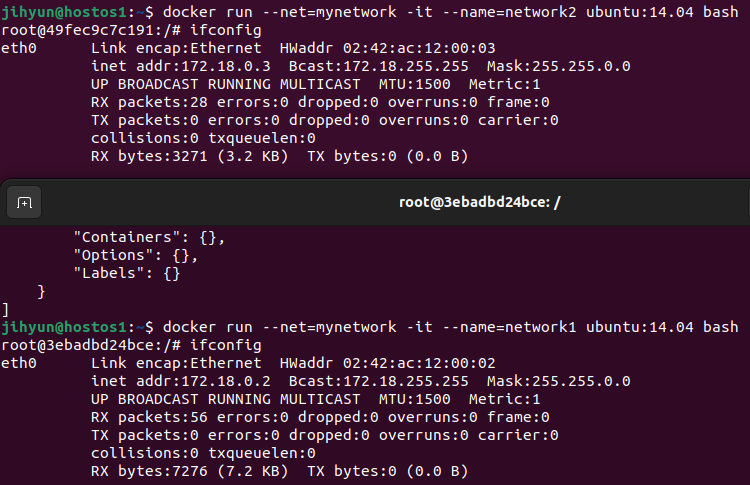
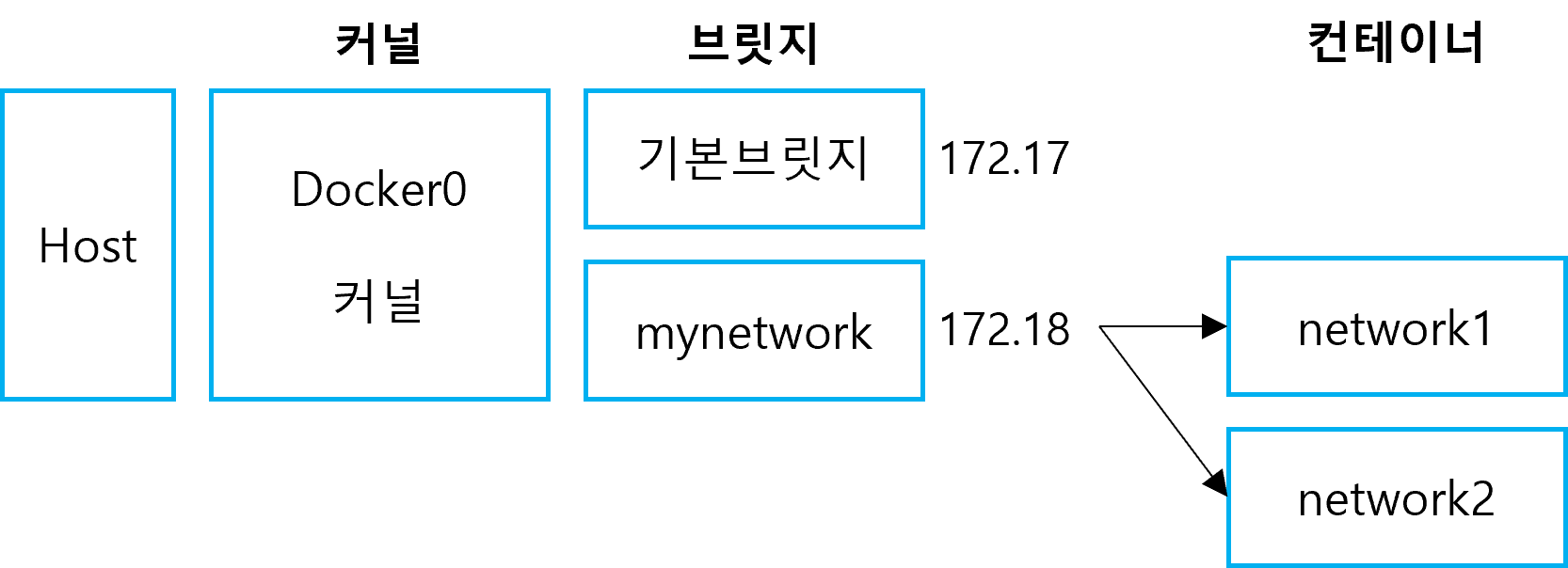
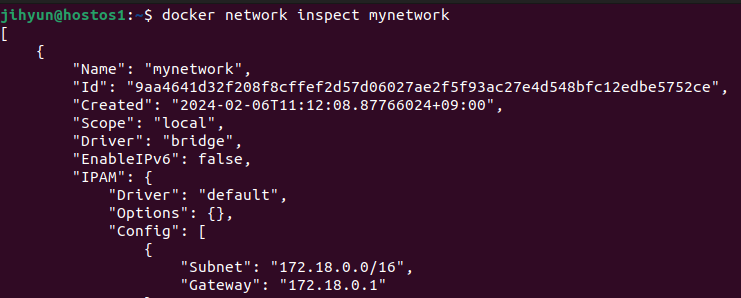
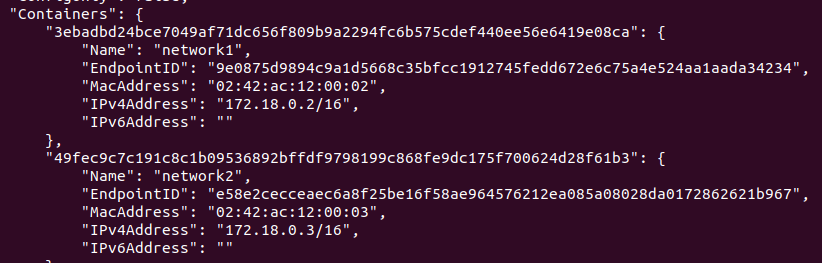
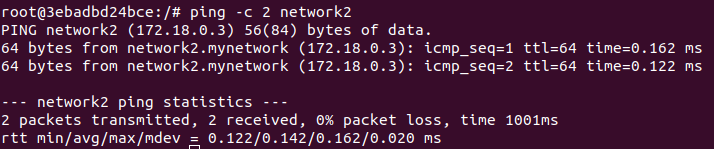
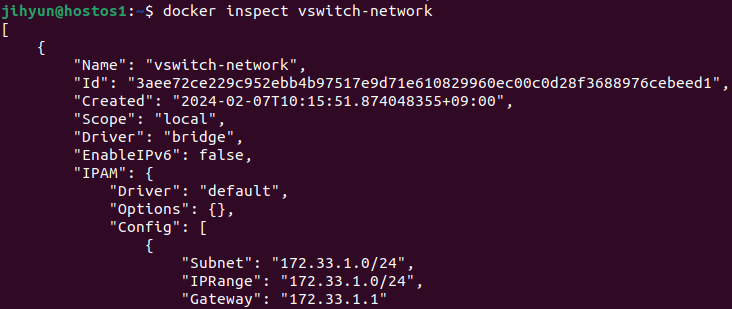
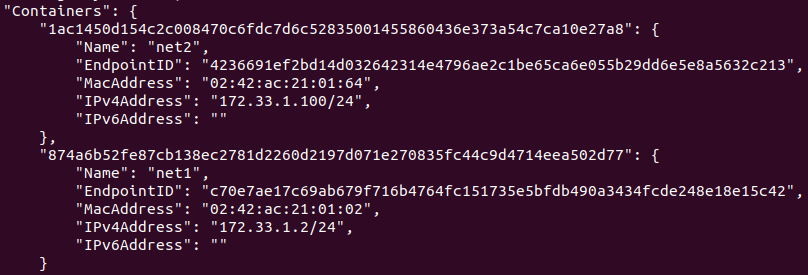
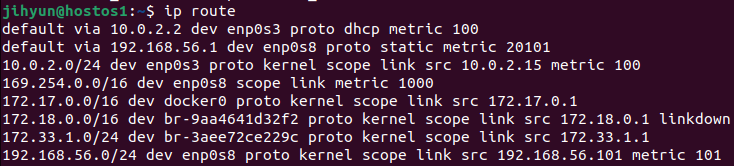
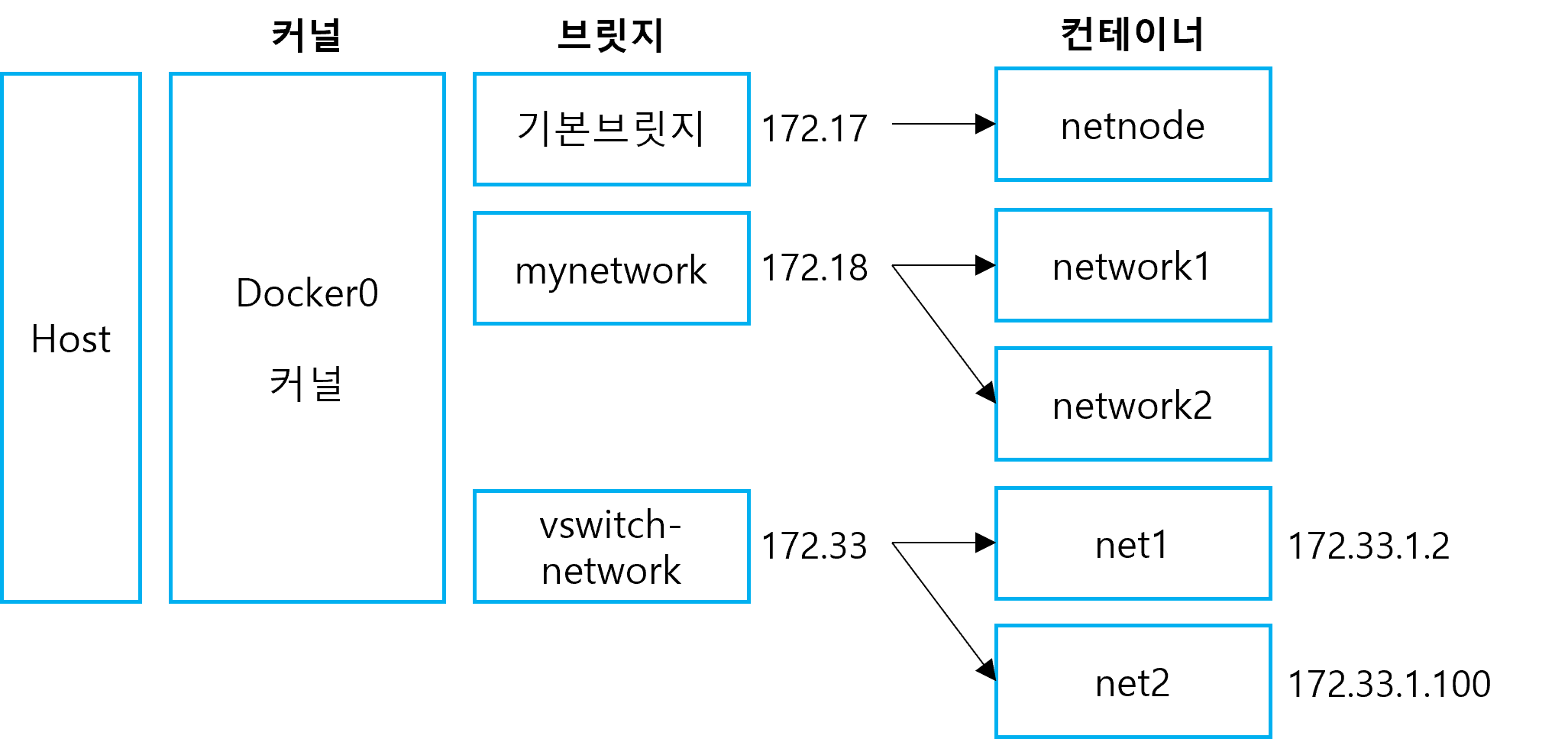
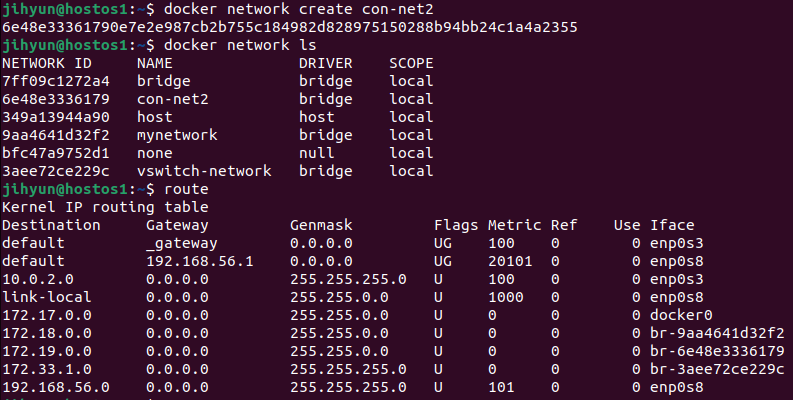
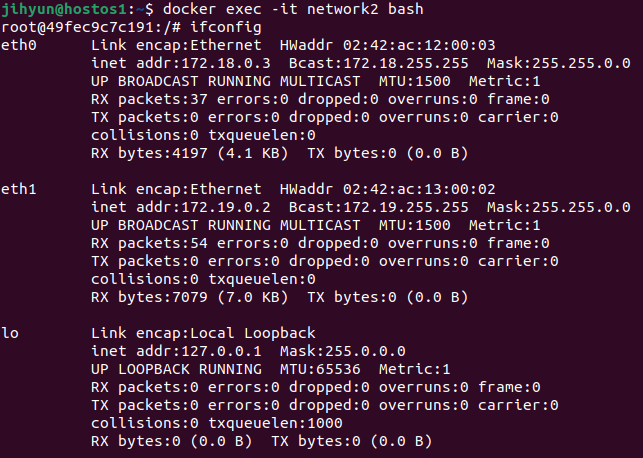
먼저, haproxy-network라는 네트워크를 생성하고 ls와 route 명령어로 조회해보면 172.21번대 대역을 사용하는 것을 확인할 수 있다.

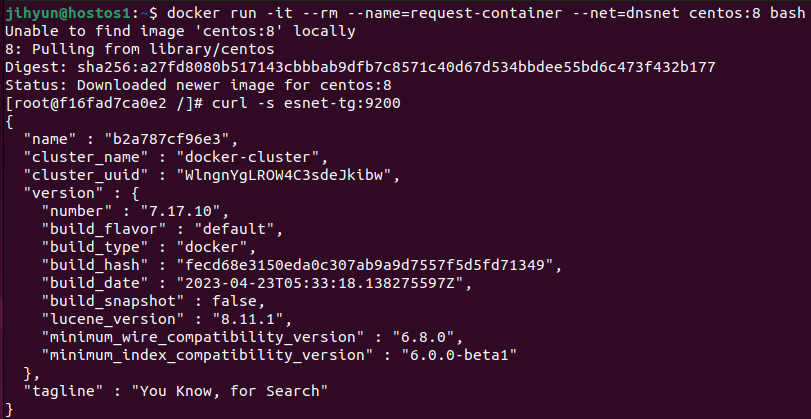
chadchae1009/haproxy:echo를 받아오고 실행했다.

컨테이너 상태를 확인해보면 위와 같이 잘 띄워졌고, 8080포트를 이용하고 있는 것을 확인할 수 있다.
global
stats socket /var/run/api.sock user haproxy group haproxy mode 660 level admin expose-fd listeners
log stdout format raw local0 info
defaults
mode http
timeout client 10s
timeout connect 5s
timeout server 10s
timeout http-request 10s
log global
frontend stats
bind *:8404
stats enable
stats uri /
stats refresh 10s
frontend myfrontend
bind :80
default_backend webservers
backend webservers
server s1 서버명:포트 check // 172.17.0.x:8080
server s2 서버명:포트 check // 컨테이너명:8080
server s3 서버명:포트 check
위와 같은 haproxy.cfg 파일을 생성해준다.
global 부분은 기본 설정이고, defaults의 mode는 http를 줄 경우 L7, tcp를 줄 경우 L4이다.
frontend stats의 경우 haproxy의 통계를 잡기 위해 8404번 포트를 오픈했다.
frontend myfrontend는 디폴트 설정에 대한 그룹설정으로 80번 포트로 들어오는 것을 webservers로 보낸다는 의미이다.
backend webservers에는 해당 리버스 프록시가 연결해줄 서버 목록들을 적어준다.
$ docker run -d --name=haproxy-con --net=haproxy-network -p 80:80 -p 8404:8404 \
-v $(pwd):/usr/local/etc/haproxy:ro haproxytech/haproxy-alpine:2.5
위와 같이 haproxy를 설치한 후 실행한다.
$(pwd)을 이용하여 pwd 수행의 결과와 컨테이너 내부를 연결해주기 위한 볼륨설정을 해주었기 때문에 haproxy.cfg 파일을 따로 보내주지 않아도 자동으로 동기화된다.

위와 같이 8404 포트로 접속 시 report 페이지에 잘 접속되는 것을 확인할 수 있다.
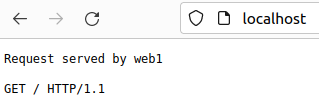
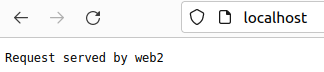
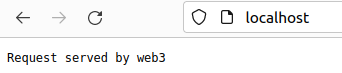
또한, localhost(80번포트)에 접속 시 위와 같이 부하분산이 적용된 백엔드 서버들을 순차적으로 오가는 것을 볼 수 있다.
2) HAproxy를 활용한 컨테이너 L4 스위치 프록시 실습 : URI 기반
global
stats socket /var/run/api.sock user haproxy group haproxy mode 660 level admin expose-fd listeners \
log stdout format raw local0 info
defaults
mode http
timeout client 10s
timeout connect 5s
timeout server 10s
timeouthttp-request 10s
log global
frontend stats
bind *:8404
stats enable
stats uri /
stats refresh 10s
frontend myfrontend
bind :80
default_backend webservers
acl 서버명1 path_beg /서버명1
acl 서버명2 path_beg /서버명2
acl 서버명3 path_beg /서버명3
use_backend 서버명1_backend if 서버명1
use_backend 서버명2_backend if 서버명2
use_backend 서버명3_backend if 서버명3
backend webservers
balance roundrobin
server s1 서버명1:포트 check
server s2 서버명2:포트 check
server s3 서버명3:포트 check
backend 서버명1_backend
server s1 서버명1:포트 check
backend 서버명2_backend
server s2 서버명2:포트 check
backend 서버명3_backend
server s3 서버명3:포트 check
위와 같이 haproxy.cfg 파일을 수정해준다.
acl과 path_beg은 우측의 /서버명으로 접근 시 좌측의 서버명으로 이동시킨다. 또한, roundrobin 방식으로 배정된다.
이는 서버명/추가uri를 붙이는 경우 추가 uri로 특정 서버를 구분할 수 있게 된다.


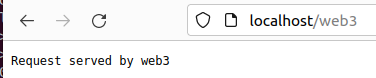
위와 같이 특정 uri로 구분이 가능한 것을 확인할 수 있다.
하지만, 이 방식에서는 사용자가 좀 더 몰릴 것으로 예상되는 uri에 더 많은 자원을 배정하기에는 무리가 있다.
따라서 다음과 같은 방식으로 특정 URI에 서버를 여러개 붙일 수 있다.
global
stats socket /var/run/api.sock user haproxy group haproxy mode 660 level admin expose-fd listeners \
log stdout format raw local0 info
defaults
mode http
timeout client 10s
timeout connect 5s
timeout server 10s
timeouthttp-request 10s
log global
frontend stats
bind *:8404
stats enable
stats uri /
stats refresh 10s
frontend myfrontend
bind :80
default_backend webservers
acl 서버명1 path_beg /uri1
acl 서버명2 path_beg /uri1
acl 서버명3 path_beg /uri2
acl 서버명4 path_beg /uri2
use_backend 그룹명1_backend if 서버명1
use_backend 그룹명1_backend if 서버명2
use_backend 그룹명2_backend if 서버명3
use_backend 그룹명2_backend if 서버명4
backend webservers
balance roundrobin
server s1 서버명1:포트 check
server s2 서버명2:포트 check
server s3 서버명3:포트 check
server s4 서버명4:포트 check
backend 그룹명1_backend
server s1 서버명1:포트 check
server s2 서버명2:포트 check
backend 그룹명2_backend
server s3 서버명3:포트 check
server s4 서버명4:포트 check
이제 URI가 1인지 2인지에 따라 전달되는 서버가 달라지기 때문에 URI 별로 프록시 설정이 가능하다.
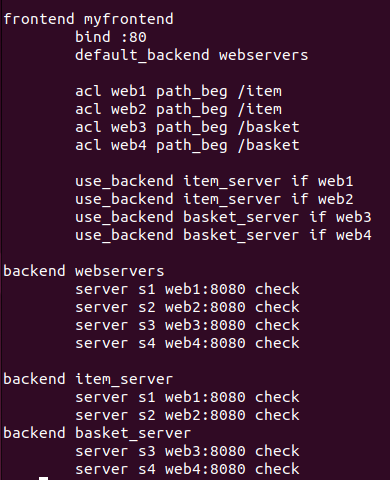
위와 같이 수정해주면 된다.

위와 같이 4개의 컨테이너를 생성 및 실행해준다.

마지막으로 테스트해보기 위한 컨테이너를 실행해보면 다음과 같은 결과를 확인할 수 있다.
localhost/80 : web 1, 2, 3, 4가 로드밸런싱 ∵ default_backend (round robin 방식)
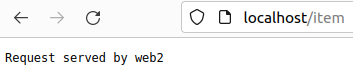
localhost/item : web 1, 2가 로드밸런싱 ∵ item_server 그룹
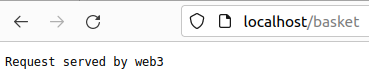
localhost/basket : web 3, 4가 로드밸런싱 ∵ basket_server 그룹