1. Protocol
1) 개념
- 원활한 통신을 위한 규칙
- 정보의 송수신측 또는 네트워크 내에서 사전에 약속된 규약 또는 규범
- 연결과정, 통신회선에서 접속방식, 통신회선을 통해 전달되는 정보의 형태, 오류발생에 대한 제어, 송수신측 간의 동기 방식 등에 대한 약속
2) 주요요소
- 구문(Syntax) : 데이터의 형식, 부호화, 신호레벨 등이 어떠한 구조와 순서로 표현되어있는지
- 의미(Semantics) : 각 비트가 갖는 의미로 패턴에 대한 해석과 해석에 따른 전송제어, 오류수정 등에 관한 제어정보를 규정
- 타이밍(Timing) : 두 개체 간의 통신속도를 조정하거나 메시지의 전송시간 및 순서 등에 대한 특성
2. OSI 7계층
1) 개념
- ISO에서는 개방형 시스템 간 상호접속을 위해 표준화된 네트워크 구조를 제공하는 기본 참조모델을 제정
- 다른 기종 간의 상호 접속을 위한 가이드라인 제시
- 상위 계층 : 사용자가 통신을 쉽게 이용할 수 있도록 도와주는 역할
- 하위 계층 : 효율적이고 정확한 전송과 관계된 일을 담당
2) 계층구조

- 7계층 구조는 비슷한 기능을 갖는 모듈을 동일 계층으로 분할
- 각 계층 간의 독립성 유지
- 한 모듈에 대한 변경이 다른 전체 모듈에 미치는 영향 최소화
- 2개의 그룹으로 분리 → 상위 3계층 : 이용자가 메시지를 교환할 때 사용, 하위 4계층 : 메시지가 호스트에서 사용
| 계층 | 특징 | 데이터 종류 | |
| 7 | 응용계층 | - 각종 응용서비스 제공 - 네트워크 관리 |
메시지 |
| 6 | 표현계층 | - 네트워크 보안(암/복호화) - 압축/압축해제, 포맷 변환 수행 |
|
| 5 | 세션계층 | - 소켓 프로그램 - 동기화 - 세션 연결/관리/종료 |
|
| 4 | 전송계층 | - 데이터 전송보장 - 흐름 제어 - Quality Of Services(QOS) |
세그먼트 |
| 3 | 네트워크계층 | - 통신경로 설정, 중계기능 담당 - 라우팅, 혼잡제어 - 데이터그램, 가상회선 방식 - IPv4, IPv6 |
패킷 |
| 2 | 데이터링크계층 | - 오류제어, Frame화 - 매체제어(MAC) - 에러검출, 에러정정, 흐름제어 |
프레임 |
| 1 | 물리계층 | - 물리적 연결설정, 해제 - 전송방식, 전송매체 |
비트 스트림 |
① 물리 계층
- 데이터를 물리 매체 상으로 전송하는 역할을 담당
- 물리적 링크의 설정/유지/해제 담당
- 상용자 장비와 네트워크 종단장비 사이의 물리적, 전기적 인터페이스 규정에 초점
- 전송 선로의 종류에 따른 전송 방식과 인코딩 방식 결정
- 송신 측 물리 계층은 데이터링크 계층으로부터 받은 데이터를 비트단위로 변환
- 수신 측 물리 계층은 전송 받은 비트를 데이터링크 계층의 데이터로 올림
② 데이터링크 계층
- 물리 계층에서 전송하는 비트들의 동기 및 식별 기능, 원활한 데이터 전송을 위한 흐름제어 기능, 안전한 데이터 전송을 위한 오류제어 기능
- 헤더 : 데이터의 시작을 나타내는 표시와 목적지 주소 포함
- 트레일러 : 데이터에 발생한 전송 오류를 검출하기 위한 오류 검출 코드 포함
- 두 sub 계층으로 구성
→ LLC(Logical Link Control sublayer) : 논리적 연결제어
→ MAC(Media Access Control) : 장비와 장비 간의 물리적인 접속
③ 네트워크 계층
- 송신 측에서 수신 측까지 데이터를 안전하게 전달하기 위해 논리적 링크 설정
- 상위 계층 데이터를 작은 크기의 패킷으로 분할하여 전송
- 개방형 시스템 사이에서 네트워크의 연결을 관리하고 유지하며 해제
- 스위칭 : 패킷의 수신 주소를 보고 정해진 방향으로 전송, 동작속도 빠름
- 라우터 : 라우팅 테이블을 찾아 알고리즘으로 최단 경로 계산 → 계산을 통해 전송경로를 결정 후 전송하여 스위치보다 동작 속도 느림
- 네트워크 주소는 발신지로부터 목적지까지 동일 (물리주소는 패킷이 이동될 때마다 변경)
④ 전송 계층
- 하위 계층의 첫 단계
- 세션을 맺고 있는 두 사용자 사이의 데이터 전송을 위한 종단간 제어
- 송신 컴퓨터의 응용프로그램(프로세스)에서 최종 수신 응용프로그램(프로세스)으로 전달
⑤ 세션 계층
- 세션이라 불리는 연결 확립 및 유지
- 효율적인 세션 관리를 위해 짧은 데이터 단위로 나눈 후 전송계층으로 내림
⑥ 표현 계층
- 송수신자가 공통으로 정보를 이해할 수 있도록 데이터 표현방식을 바꾸는 기능
- 데이터의 보안과 효율적인 전송을 위해 암호화와 압축을 수행하여 세션 계층으로 내림
⑦ 응용 계층
- 최상위 계층으로 응용 프로세스 네트워크 환경에 접근하는 수단을 제공
- 응용 프로세스들이 상호 간에 유용한 정보교환을 할 수 있도록 하는 창구 역할을 담당
3) 피어-투-피어(Peer-to-Peer) 간의 통신
- OSI 참조모델의 i번째 계층에서 다른 시스템의 i번째 계층과 통신하기 위해서는 상위계층의 메시지와 더불어 프로토콜 - 제어정보(PCI)를 이용
- 피어-투-피어 프로세스 : 임의의 계층에서 상대편 동일 계층의 모듈과 통신하는 프로세스
4) 캡슐화와 역캡슐화
① 캡슐화
- 어떤 것을 다른 것에 포함시킴으로써 포함된 것이 외부에서 보이지 않도록 함
- 프로토콜 데이터 단위를 다른 프로토콜 데이터 단위의 데이터 필드 부분에 위치시키는 기술
② 역캡슐화
- 캡슐화 이전으로 복원시키거나 제거
- 캡슐화의 반대 동작
- 프로토콜 데이터 필드에 위치하고 있는 데이터 단위를 추출
※ 각 레벨의 데이터 PDU(Protocol Data Unit)
| PDU 이름 | 계층 |
| 데이터(data) | 응용 계층 PDU |
| 세그먼트(segment) | 전송 계층 PDU |
| 패킷(packet) | 인터페이스 계층 PDU |
| 프레임(frame) | 네트워크 접근 계층 PDU |
| 비트(bit) | 매체를 통해 이진 데이터로 물리적 전송을 위해 사용되는 PDU |
→ 송신 단에서는 7계층에서 1계층으로 각각의 PDU를 추가하여 데이터를 캡슐화하고, 수신 단에서는 1계층에서 7계층으로 각각의 PDU를 제거하여 데이터를 얻는 비캡슐화 과정을 겪게 된다.
3. TCP/IP 4계층
1) 개념
- 미국 국방부 고등 연구 계획국에서 만든 연구 네트워크의 일부로 설계 (ARPAnet)
- 현재는 TCP와 IP가 공식 표준
- 다양한 기종의 컴퓨터가 하나로 묶이는 인터네트워킹 구조를 만듦
- 여러가지 프로토콜의 조합을 의미
- 4계층으로 구성 : 데이터링크, 네트워크, 전송, 응용계층
2) 계층구조
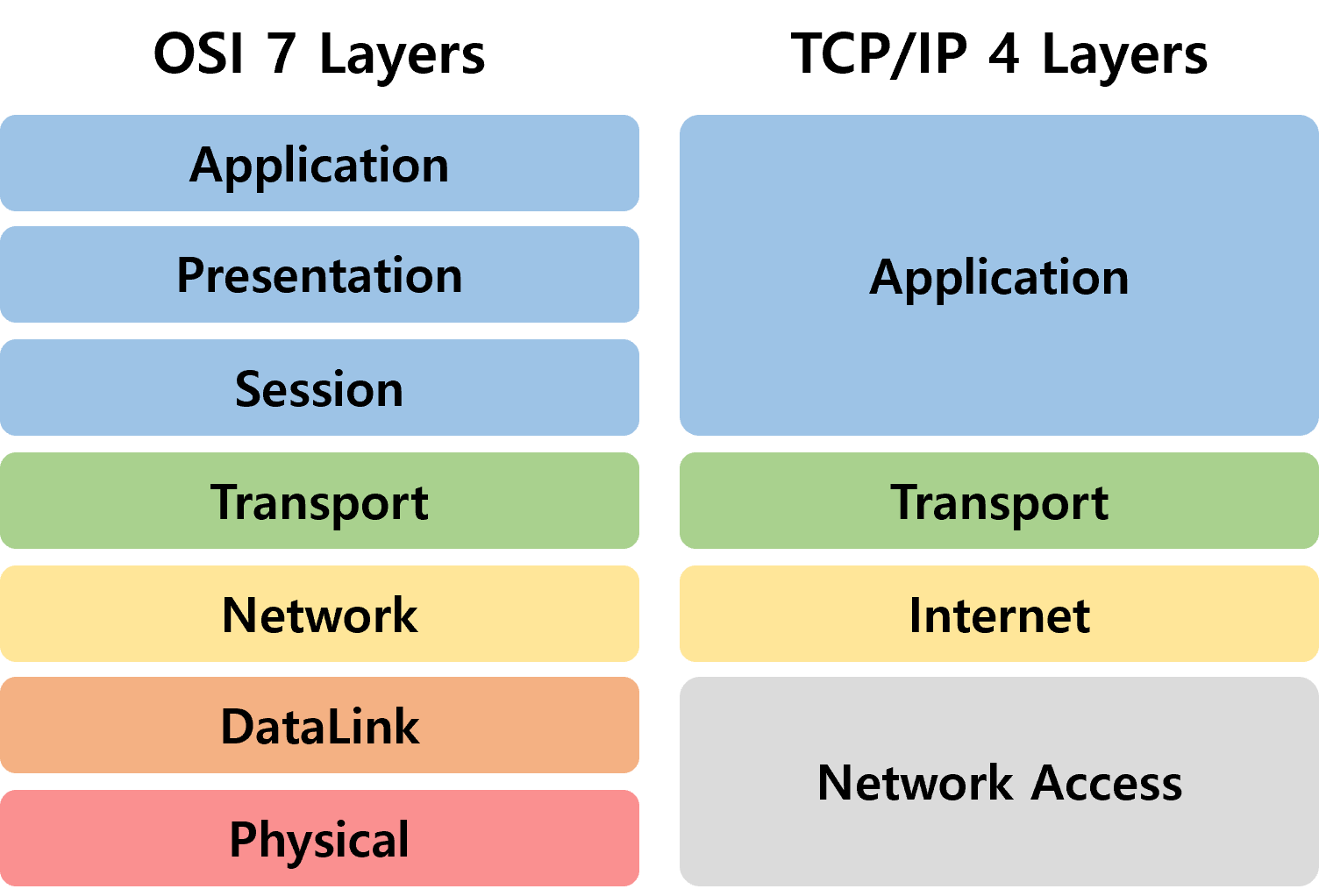
① 네트워크 연결 계층
- 데이터를 송수신하는 역할
② 인터넷 계층
- 주소 관리, 포장, 라우팅하는 역할
- IP(Internet Protocol) : 호스트들과 네트워크에서 주소 관리, 패킷 라우팅
- ARP(Address Resolution Protocol) : 같은 네트워크에 위치한 호스트들의 하드웨어 주소를 얻는 데 사용
- ICMP(Internet Control Message Protocol) : 패킷 전송에 관한 에러 메시지 처리
③ 전송 계층
- 호스트들 간의 통신 제공, 2개의 프로토콜 존재
→ TCP(Transmission Control Protocol)
- 연결지향
- 데이터의 확실한 전송을 위해 수신 측으로 받았다는 확인 메시지 요구
→ UDP(User Datagram Protocol)
- 비연결지향
- 실시간으로 패킷을 전송하여 빠르나 패킷의 정확한 전달을 보장하지 않음
※ TCP와 UDP의 차이점
| 서비스 | TCP | UDP |
| 신뢰성 | - 패킷이 목적지까지 도달했는지 확인 - 패킷이 도달할 때마다 ACK를 수신 - 신뢰성 있는 프로토콜 |
- ACK를 사용하지 않음 - 패킷이 그들의 목적지에 도달되는 것을 보장하지 않음 - 신뢰성 없는 프로토콜 |
| 연결 | - 연결 지향적 - 핸드쉐이킹 과정 수행 |
- 비연결지향적 |
| 패킷 순서 | - 패킷 내에 순서 번호 사용 | X |
| 혼잡 제어 | O | X |
| 용도 | - 신뢰성 있는 전송 | - 스트리밍 비디오와 브로드캐스트 등 실시간 전송 |
| 속도의 오버헤드 | - 상당한 양의 자원을 사용하며 UDP보다 느림 | - 더 적은 자원을 사용하고 TCP보다 빠름 |
④ 응용 계층
- 어플리케이션이 네트워크에 접근 가능하도록 함
4. Port, well known port
1) 포트 주소의 의미와 할당 원칙
① 포트
- 일종의 논리적인 접속 장소
- 포트 번호는 인터넷이나 기타 다른 네트워크 메시지가 서버에 도착했을 때 전달돼야 할 특정 프로세스를 인식하기 위한 방법
- TCP와 UDP에서 포트번호는 15비트 정수의 형태
② 포트번호와 소켓
- 통신을 위해 TCP 헤더에 송수신자 포트 정보를 삽입하여 패킷 생성
- 패킷을 서버로 전달하여 프로세스와 연결되면 서비스 이용 가능
- 포트 번호는 16비트, 0~65535번까지 존재, 0~1023번은 가능하면 사용 X (웰 노운 포트)
- 주요 포트번호 : root의 권한이 필요한 포트
2) well known port (잘 알려진 포트)
- 어떤 특권을 가진 서비스에 의해 사용될 수 있도록 예약되어 있음
- 루트 권한으로만 포트를 열 수 있음
- 루트 권한으로 실행된 프로그램만이 이 포트에서 데이터를 수신할 수 있지만, 권한에 상관없이 모든 프로그램이 이 포트로 데이터를 보낼 수 있음
| 프로토콜 | 포트 | 용도 |
| ECHO | 7 | 두 장비의 연결 확인 |
| FTP data | 20 | 파일 전송 프로토콜, 데이터 포트, FTP는 두 개의 포트 사용 |
| FTP | 21 | PUT, GET 등의 FTP 명령 전송 시 사용 |
| SSH | 22 | 암호화된 원격 로그인에 사용 |
| TELNET | 23 | 대화 방식의 원격 명령 라인 세션에 사용, 암호화되지 않느 텍스트 송신 |
| SMTP | 25 | 장비 간의 메일 전송 |
| TIME | 37 | 1990년 1월 1일 자정 이후의 경과 시간을 초로 반환 |
| DNS | 53 | 호스트 도메인의 이름을 네트워크 주소로 바꾸거나 그 반대의 변환 수행 |
| HTTP | 80 | www 기반의 프로토콜 |
| HTTPS | 43 | HTTP over SSL (암호화된 전송) |
5. HTTP, URL
1) 개념
- 인터넷 상에서 데이터를 주고 받기 위해 클라이언트와 서버 사이에 이루어지는 요청/응답 프로토콜
- 어떤 종류의 데이터든지 전송 가능, 주로 HTML 문서를 주고받음
- 사용하는 포트 번호 : 80번
- 주로 웹브라우저를 이용하여 통신
- 단점 : 인터넷 상에서 받은 데이터는 평문이 그대로 노출 → 네트워크 상에서 패킷이 그대로 노출되는 취약점 발생
2) HTTP Header
- HTTP 통신을 위해 필요한 정보들이 입력되어 있는 데이터 영역
| Host | 요청이 전송되는 타겟의 host URL 주소 |
| Accept | 클라이언트가 허용할 수 있는 파일 형식 |
| User-Agent | 요청을 보내는 클라이언트의 정보 |
| Referer | 현재 요청된 페이지 이전의 페이지 주소 |
| Cookie | 클라이언트에게 설정된 쿠키 정보 |
| Content-Type | Request에 보내는 데이터의 type 정보 |
| Content-Length | Request에 보내는 데이터의 길이 |
3) HTTP Method
- HTTP 통신의 형태를 결정
| GET | - URI(URL)가 가진 정보를 검색하기 위해 서버 측에 요청하는 형태 |
| POST | - URI(URL)에 폼 입력을 처리하기 위해 구성한 서버 측 스크립트 혹은 CGI 프로그램으로 구성 - Form Action과 함께 전송 - 데이터 부분에 요청 정보가 들어감 |
| HEAD | - GET과 유사한 방식 - 헤더 정보 이외에는 어떤 데이터도 보내지 않음 - 웹 서버의 다운 여부 점검이나 웹 서버 정보를 얻기 위해 사용 |
| OPTIONS | - 시스템에서 지원되는 메소드 종류 확인 가능 |
| PUT | - POST와 유사한 전송 구조 - 헤더 이외에 메세지가 함께 전송 - 원격지 서버에 지정한 콘텐츠를 저장하기 위해 사용 - 홈페이지 변조에 악용 |
| DELETE | - PUT과 반대 개념 - 원격지 웹 서버에 파일을 삭제하기 위해 사용 |
| TRACE | - 원격지 서버에 루프백 메세지를 호출하기 위해 사용 |
| CONNECT | - 웹 서버에 프록시 기능을 요청할 때 사용 |
4) HTTP Content-Type
- HTTP 헤더에 보내지는 데이터
- 표준 MIME Type의 하나
→ 브라우저는 데이터를 나타내는데 어떤 종류의 파일 stream인지 알게 됨
→ 서버에서 데이터를 해석할 때 중요한 역할을 함
| Text | 사람이 읽고 이해할 수 있는 문자열 |
| Image | 그림 데이터 |
| Audio | 음성 데이터 |
| Video | 동영상 데이터 |
| Application | 모든 종류의 이진 데이터 |
| Multipart | 복수의 데이터로 이루어진 복합 데이터 |
| Message | 전자 메일 메세지 |
| Model | 복수 차원으로 구성하는 모델 데이터 |
5) URL
- URI (URL) : Uniform Resource Identifier의 약자로 리소스를 식별하기 위한 식별자
- URL은 Uniform Resource Locator의 약자로 리소스의 위치를 식별하기 위한 URI의 하위 개념
- URI는 Scheme, Authority (Userinfo, Host, Port), Path, Query, Fragment의 구성 요소를 가짐
- 자주 쓰이는 웹 URI 구성 요소
| Scheme | 웹 서버에 접속할 때 어떤 프로토콜을 이용할지에 대한 정보를 담고 있음 |
| Host | 접속할 웹 서버의 호스트(서버 주소)에 대한 정보를 가지고 있음 |
| Port | 접속할 웹 서버의 포트에 대한 정보를 가지고 있음 |
| Path | 접속할 웹 서버의 경로에 대한 정보를 가지고 있음, '/' 문자로 구분 |
| Query | 웹 서버에 전달하는 파라미터이며 URI에서 '?' 문자 뒤에 붙음 |
| Fragment | 메인 리소스 내에 존재하는 서브 리소스에 접근할 때 이를 식별하기 위한 정보를 담고 있으며 URI에서 '#' 문자 뒤에 붙음 |
7. TCP/IP
→ 인터넷에 연결된 다른 종류의 컴퓨터끼리 상호 데이터를 주고받을 수 있도록 한 인터넷 표준 프로토콜
(TCP : 데이터를 패킷으로 나누고 묶는 역할, IP : 명령이 올바르게 전송되도록 하며 전달되지 못한 패킷은 재전송)
1) TCP(Transmission Control Protocol) 주요 특징
- 신뢰성 있음 : 패킷 손실, 중복, 순서바뀜 등이 없도록 보장
- 연결지향적
: 느슨한 연결(Loosly Connected)을 가짐
: 연결 관리를 위한 연결 설정 및 연결 해제 필요
: 양단간 어플리케이션/프로세스는 TCP가 제공하는 연결성 회선을 통하여 서로 통신
- TCP 연결의 식별, 다중화, 포트번호
- 전이중 전송방식/양방향성
- 멀티캐스트 불가능
- 세그먼트화 처리 : 데이터를 패키징 처리
- 흐름제어, 혼잡제어
- 비실시간적 응용
2) IP(Internet Protocol) 주요 특징
- 신뢰성 및 흐름제어 기능이 전혀 없음
- 비연결성 데이터그램 방식
- 패킷의 완전한 전달을 보장하지 않음
- IP 헤더 내에 수신 및 발신 주소를 포함
- IP 헤더 내 최상위 바이트(MSB)를 먼저 보냄
- 경우에 따라 단편화가 필요함
- 모든 상위 계층 프로토콜들이 IP 데이터그램에 살려서 전송됨
3) IPv4 주소 체제
- 32비트의 IP 주소를 보기 쉽게 표시하기 위해 4바이트 단위로 나누고 10진수로 표시하는 표현 방식이 널리 사용
- IP 주소는 네트워크 식별자 필드와 호스트 식별자 필드의 두 부분으로 구성되며 각 필드에서 사용되는 비트 수에 따라 5개의 클래스로 나눔
① 클래스별 IP 주소 내용
| 클래스 A | - 첫번째 비트가 0인 IP 주소 - 상위 1바이트 : 네트워크 주소, 하위 3바이트 : 호스트 주소 - 큰 규모의 호스트를 갖는 기관에 할당 |
| 클래스 B | - 처음 두 비트의 값이 10인 주소 - 상위 2바이트 : 네트워크 주소, 하위 2바이트 : 호스트 주소 |
| 클래스 C | - 처음 3비트의 값이 110인 주소 - 상위 3바이트 : 네트워크 주소, 하위 1바이트 : 호스트 주소 - 작은 규모의 네트워크에 할당 |
| 클래스 D | - 처음 4비트의 값이 1110인 주소 - 전체 주소가 멀티캐스트용으로 사용 |
| 클래스 E | - 처음 4비트의 값이 1111인 주소 - 추후 사용을 위해 예약된 주소 |
② 패킷의 전송방법
| 전송 방식 | 설명 |
| 유니캐스트 | - 하나의 송신자가 하나의 수신자에게 패킷을 보내는 방식 |
| 멀티캐스트 | - 하나의 송신자가 다수의 수신자에게 패킷을 보내는 방식 - 특정 다수에게 전송 |
| 브로드캐스트 | - 같은 네트워크에 잇는 모든 호스트에게 패킷을 보내는 방식 - 호스트 주소를 모두 1로 설정 - 불특정 다수에게 전송 |
③ IPv4 주소 관리방식
- 서브네팅 : 이진수로 1인 부분은 네트워크 부분, 0인 부분은 호스트
- 슈퍼네팅 : 부족한 IP를 효율적으로 사용하기 위해 여러 개의 C클래스 주소를 묶어 하나의 네트워크로 구성하는 방식
④ CIDR(Classes InterDomain Routing)
- 표기법
: 비트마스크를 사용하여 점으로 구분된 10진 표기법 지정
: 서브넷 마스크에서 연속된 1의 수가 몇개인지 지정, 연속된 1은 서브넷 마스크의 맨 왼쪽 비트부터 시작
: IP 주소에서 네트워크 ID 구성, /x로 비트 수 표현
- 장점
: IPv4의 주소 공간을 효율적으로 할당
: 인터넷 라우팅 테이블의 비대화를 줄임
⑤ VLSM(Variable Length Subnet Mask)
- IP를 효율적으로 할당하여 활용
- 서로 다른 크기의 서브넷 지원
- IP 주소 공간의 일부를 잘라서 사용, 한 기관에 이미 할당된 주소 공간을 나눔
⑥ 사설 네트워크를 위한 주소할당
| 공인 IP | - 인터넷 상에 하나밖에 없는 IP로 유일 - 각 나라의 관할 기관에서 할당 |
| 사설 IP | - 인터넷 상에서 확인할 수 없으며 내부 네트워크에서만 활용 - 홈 LAN이나 회사 내부에서 마음대로 할당 |
- 사설주소 영역 : 사설 인터넷을 위해 IANA가 할당한 IP 주소 블록
| 클래스 | IP 주소 블록 | 주소 범위 |
| class A | 24비트 블록 | 10.0.0.0 ~ 10.255.255.255 |
| class B | 20비트 블록 | 172.16.0.0 ~ 172.31.255.255 |
| class C | 16비트 블록 | 192.168.0.0 ~ 192.168.255.255 |
- NAT(Network Address Translation) : 사설 IP 주소를 공인 IP 주소로 변환하는 주소 변환기
4) IPv6
- 128비트 주소 길이를 사용
- 보안문제, 라우팅 효율성 문제, QoS 보장, 무선 인터넷 지원과 같은 다양한 기능 제공
5) IPv4와 IPv6 특징 비교
| 구분 | IPv4 | IPv6 |
| 주소 길이 | 32비트 | 128비트 |
| 표시 방법 | 8비트 4부분 10진수 표시 | 16비트 8부분 16진수 표시 |
| 주소 개수 | 약 43억개 | 2^128개 |
| 주소 할당방식 | A, B, C, D 등의 클래스 단위 비순차 할당 | 네트워크 규모, 단말기 수에 따라 순차 할당 |
| 브로드캐스트 주소 | 있음 | 없음 |
| 헤더 크기 | 가변 | 고정 |
| QoS 제공 | 미흡 | 제공 |
| 보안 | IPSec 프로토콜 별도로 설치 | IPSec 자체 지원 |
| 서비스 품질 | 제한적 품질 보장 | 확장된 품질 보장 |