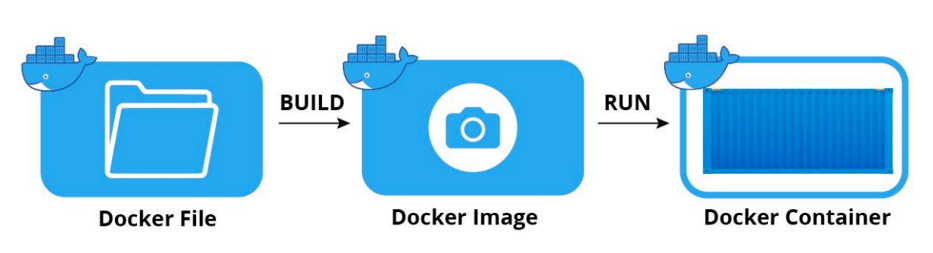
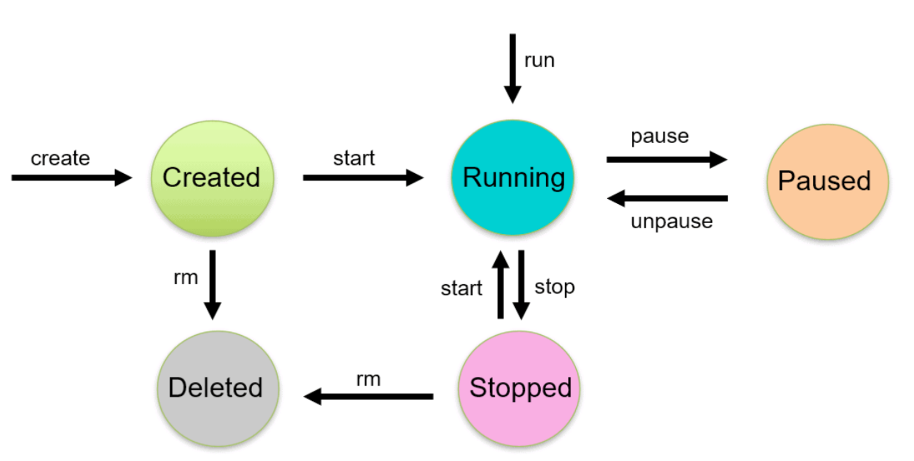
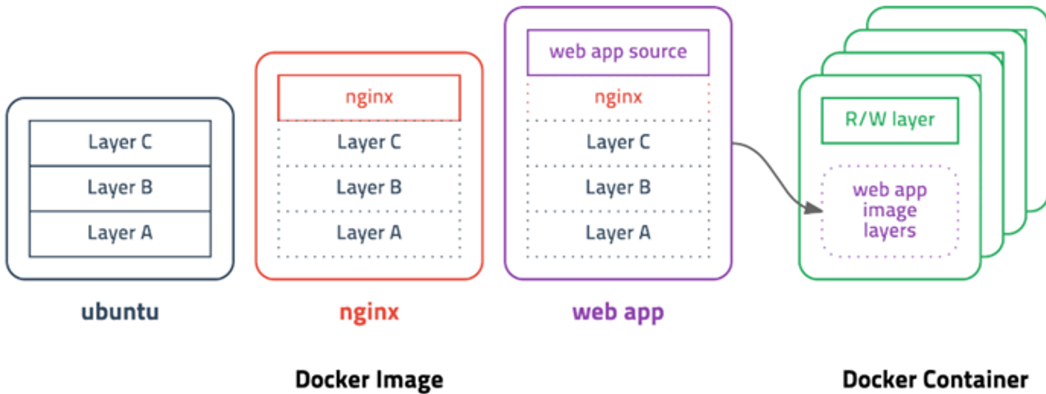
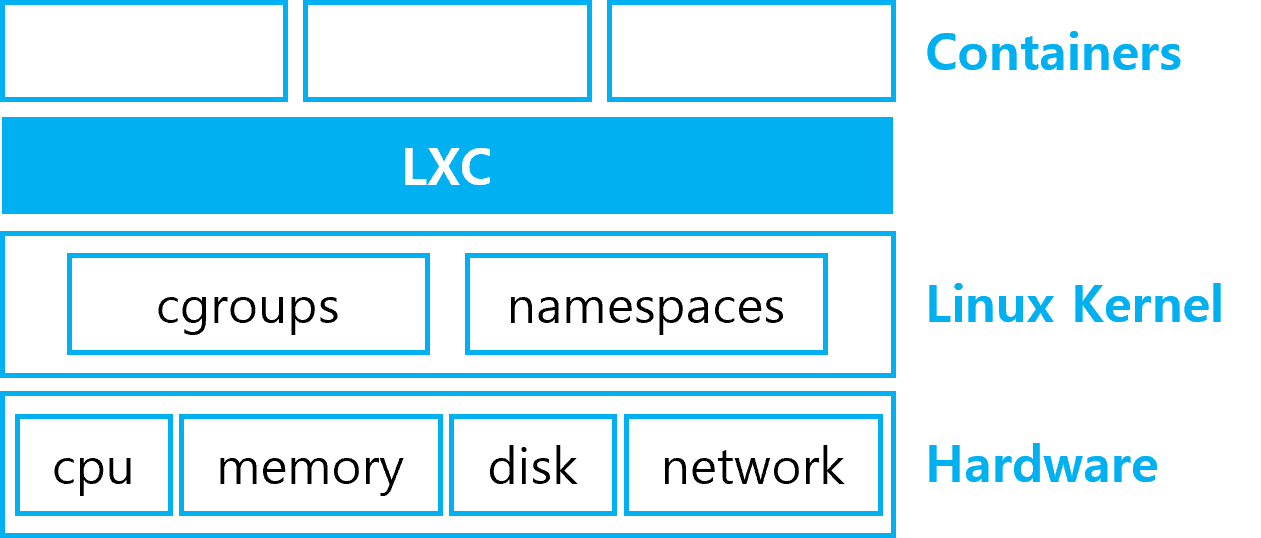
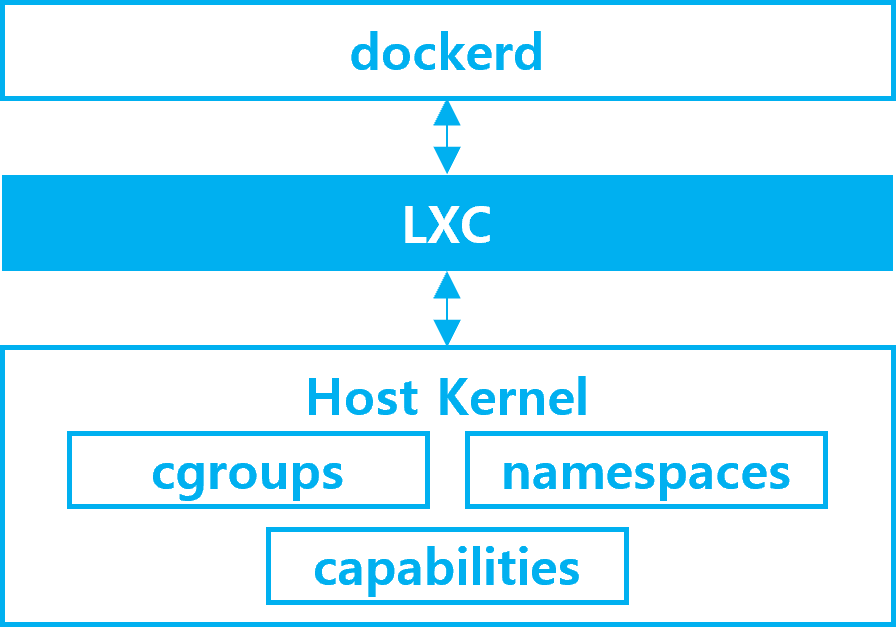
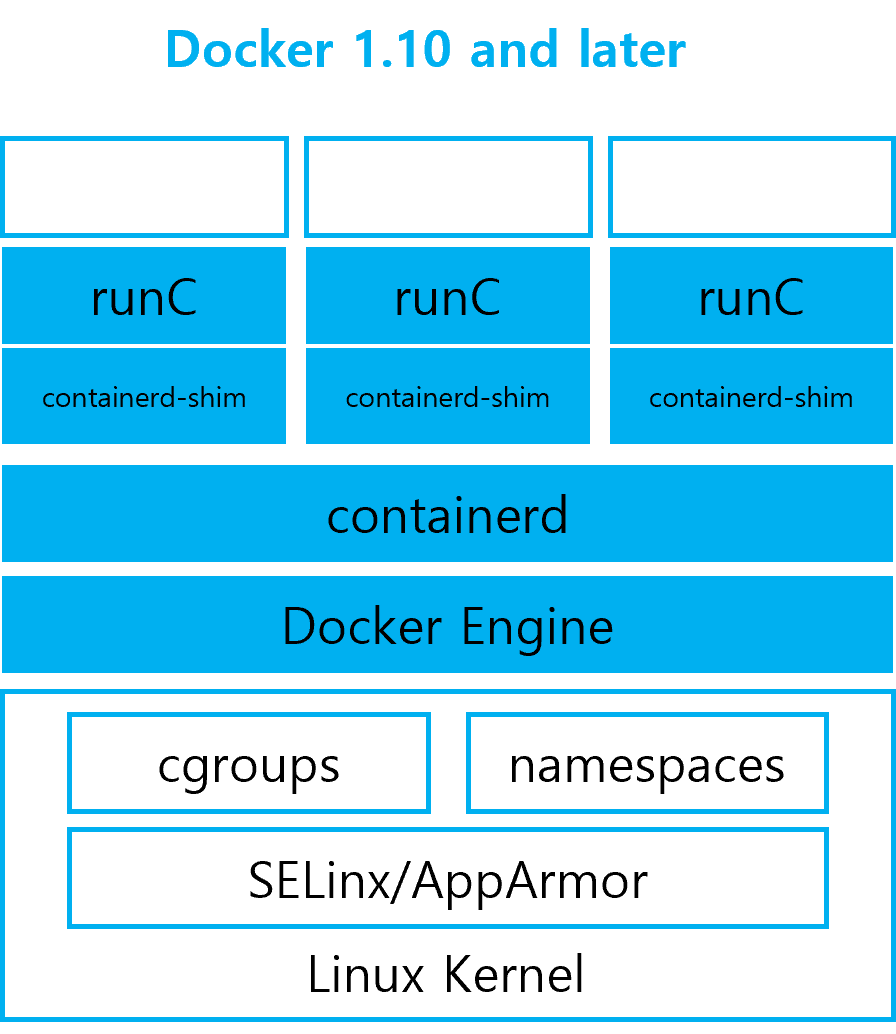
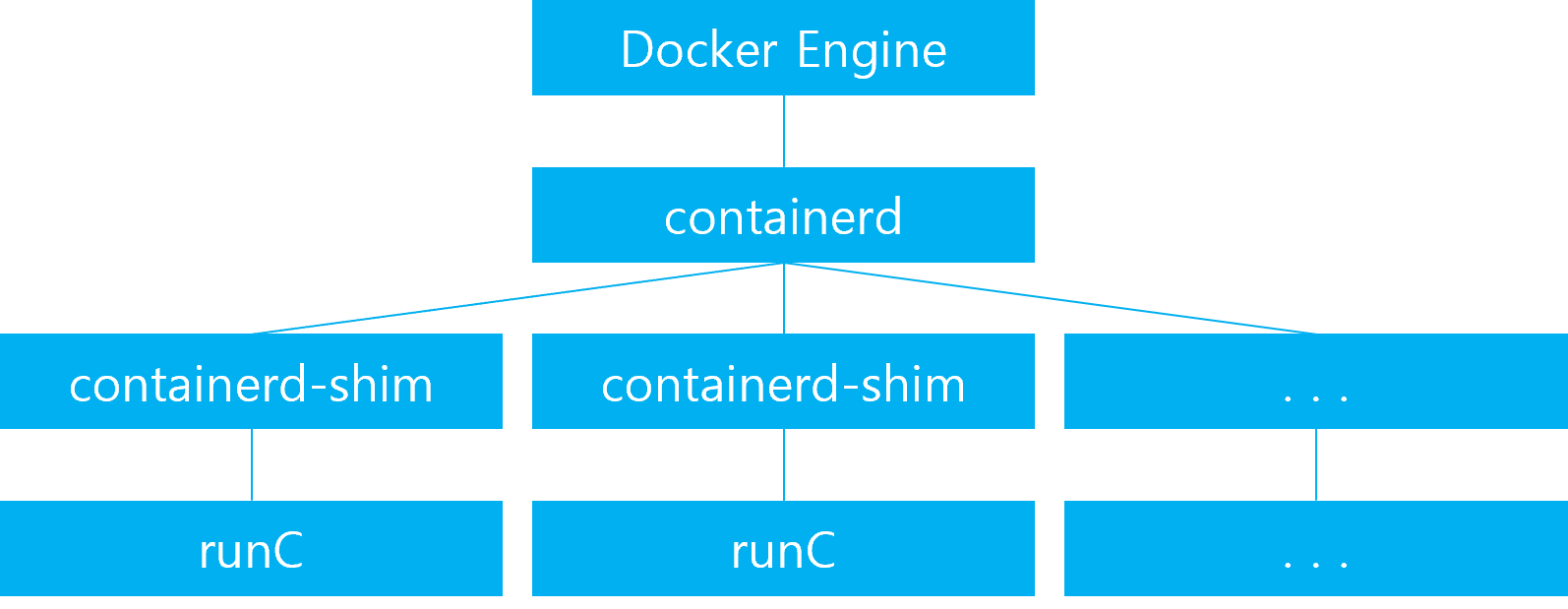
1. rocky linux 컨테이너로 띄워보기
$ docker pull rockylinux/rockylinux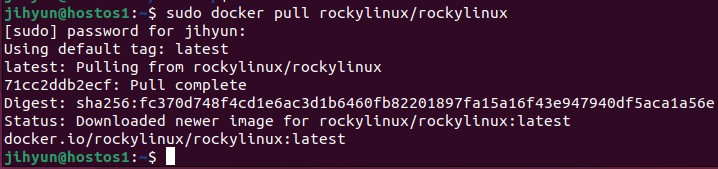
위와 같이 pull 명령어로 로키 리눅스를 받아온다.

이미지 용량을 보면 iso 파일에 비해 훨씬 경량화되어 있는 것을 확인할 수 있다.
$ docker run -it --name=rocky-container rockylinux/rockylinux 내부에서수행할명령어
run 명령어로 특정 컨테이너를 실행하고, -it 옵션을 사용하여 사용자의 명령어를 받을 수 있는 상태로 들어가도록 한다.
※ -it 옵션 : interactive 및 tty의 약자, 컨테이너 실행 시 대화형으로 실행하고 터미널을 할당하도록 지시하는 옵션
→ 컨테이너 내부에서 사용자와 상호작용하거나 명령어를 입력할 수 있음


위와 같이 도커 엔진을 통해 rocky linux로 명령어가 전달되고, 도커 엔진을 통해 host1 Ubuntu에 결과를 전달해준다.
$ docker run -it --name=rocky-container rockylinux/rockylinux bash
일회성 실행이 아닌 지속적으로 관리하고 싶다면 쉘이나 배쉬 등을 켜주는 명령어를 -it 옵션으로 넘겨주면 된다.

위와 같이 bash 쉘로 잘 들어가고 종료는 exit 명령어를 이용한다. exit으로 빠져나오는 경우는 컨테이너의 상태가 exit 상태가 된다.

위와 같이 충돌이 날 경우 컨테이너를 재기동하는 start 명령을 사용한 후 실행된 컨테이너에 exec를 이용해 명령어를 전달한다.

위와 같이 start 명령을 사용하면 up 상태로 바뀐 것을 확인할 수 있다.
$ docker exec -it rocky-container bash
이후 exec 명령어를 전달하여 재기동할 수 있고, 백그라운드에서 컨테이너를 돌게 하고 싶다면 ctrl+p+q를 입력한다.
2. 우분투 띄워보기
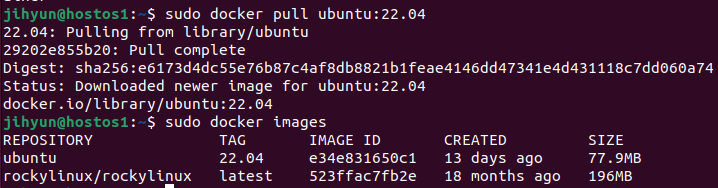
마찬가지로 pull 명령어로 우분투를 설치하고 확인해보면 이미지가 경량화된 것을 볼 수 있다.

우분투의 경우 apt update를 수행해야 기본적인 기능들을 추가로 사용할 수 있고, 대신 잡아먹는 용량도 늘어난다.

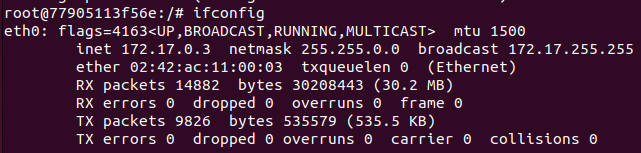
ifconfig 명령어를 사용하기 위해 net-tools를 설치한 후 확인해보면 위와 같이 잘 출력되는 것을 확인할 수 있다.
3. 도커 내부 아이피 배정 순서
도커는 특별한 설정이 없다면 무조건 docker0의 ip를 게이트웨이로 삼는 특성을 갖는다.
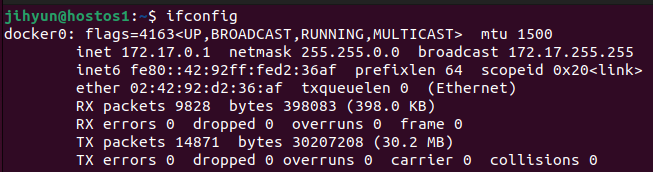
docker0의 ip 주소가 172.17.0.1이고, 가운데 17과 0은 무작위 숫자가 부여되고, 맨 마지막 숫자는 1로 시작하고 이후 요소들은 2, 3과 같이 배정한다.
$ docker inspect 컨테이너명 | grep -i ipaddress도커 호스트 자체에서 컨테이너들에게 배정된 내부 ip를 조회할 수 있다.

위와 같이 처음 생성했던 rocky-container는 ip 주소 마지막 숫자가 2인 것을 확인할 수 있다.

위와 같이 컨테이너 ip는 마지막 숫자만 다른 것을 확인할 수 있다.
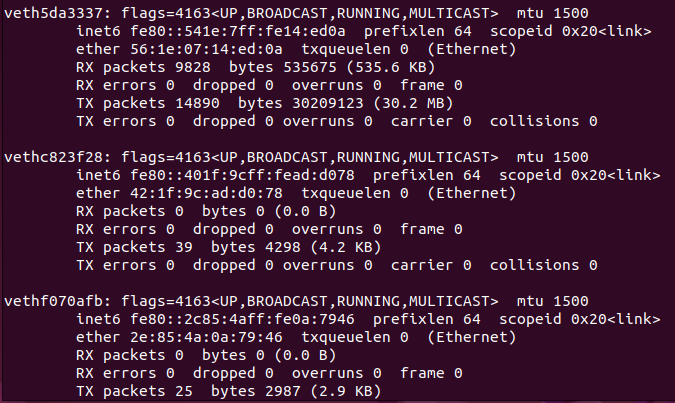
ifconfig 조회 시 가상 이더넷이 조회되는 것을 볼 수 있고,이는 호스트와 컨테이너 사이에서 매 컨테이너마다 하나씩 가상으로 생성되어 내부망 접속을 도와주며 컨테이너 개수 파악용도로 쓸 수도 있다.
4. 이미지 실존 여부 확인하기
pull이나 run으로 다운받아 실행하려는 이미지가 실제로 있는 버전인지 파악하는 것이 중요하다.

위와 같이 dockerhub에 접속하여 document를 체크하면 된다.
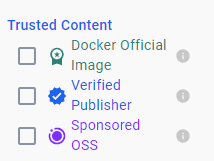
이처럼 공식 마크, 인증 마크가 있는 여러 레포를 볼 수 있다.
대부분의 벤더들이 이제 OS에 사용자가 설치할 수 있는 수단을 제공하는 것도 좋지만, 컨테이너로 배포하는 것이 더 효율적이라고 판단했기 때문에 많은 서드파티들은 도커 이미지로 업데이트되어있다.
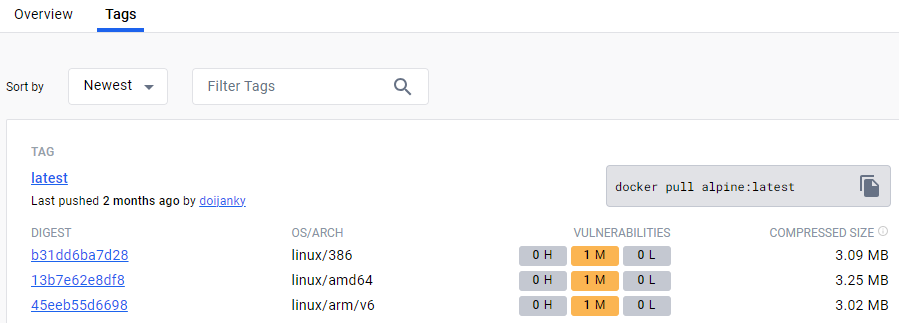
Tags 탭에서 제공되는 많은 버전을 확인할 수 있다.

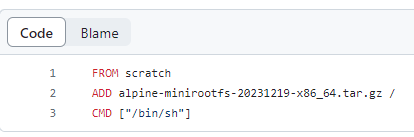
또한, overview 탭에서 Dockerfile을 제공하는 링크로 와서 아무 버전이나 클릭하면 깃허브 레포로 연결되고, 해당 이미지를 구성하기 위해 어떤 도커파일이 작성되어 있는지도 공개되어 있다.
5. alpine 버전과 그냥 버전의 차이
일반 리눅스는 iso 파일만 GB단위, 컨테이너 목적의 이미지도 용량이 크기 때문에 프로세스 구동에만 필요한 경량화 os를 사용할 수도 있음
→ alpine 리눅스
무려 5MB 정도로 해결해준다.
즉, 용량이 중요한 상황이라면 alpine 버전을 사용하여 이미지 크기를 줄일 수 있다.
6. nginx를 활용해 오픈 포트 확인하기

pull 명령어로 nginx alpine 버전으로 받아준다.
$ docker image history 방금받은이미지
위 명령어를 수행하면 EXPOSE라는 구문과 함께 오픈 포트가 공개되어 있는 것을 확인할 수 있다.
EXPOSE는 방화벽에서 외부접근을 허용하기 위해 노출시킨 포트 번호를 의미하고 위 이미지에서는 80번 포트를 기반으로 돌아가게 설계한 것을 확인할 수 있다.

다운로드했던 해당 이미지를 실행한다.

컨테이너 삭제 시 stop 상태여야만 rm 명령어를 수행할 수 있다.

8000번 포트로 포트포워딩 진행

포트포워딩이 잘 진행되었고, 실행 시 이름을 따로 지정하지 않으면 자동으로 생성해준다.
$ docker port 컨테이너명
위와 같이 추후 포트바인딩에 대한 정보 조회도 가능하다.
$ netstat -nlp | grep 포트번호
위 명령어를 통해 호스트의 몇 번 포트가 포트바인딩에 사용되고 있는지도 조회가 가능하다.
$ ps -ef | grep 프록시번호
위에서 조회한 도커프록시의 번호를 이용하여 ps -ef 명령어를 사용하면 좀 더 상세한 정보를 얻을 수 있다.
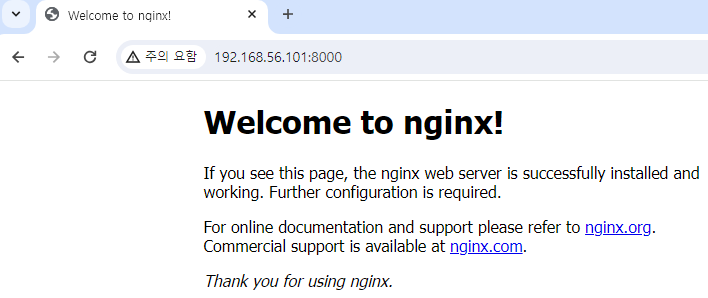
위와 같이 해당 IP와 8000번 포트로 외부에서 접속이 가능한 것을 확인할 수 있다. (NAT 이용)
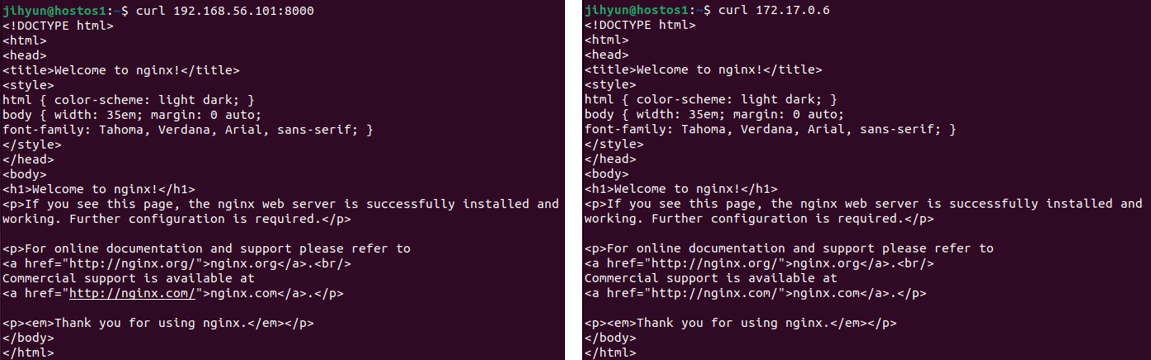
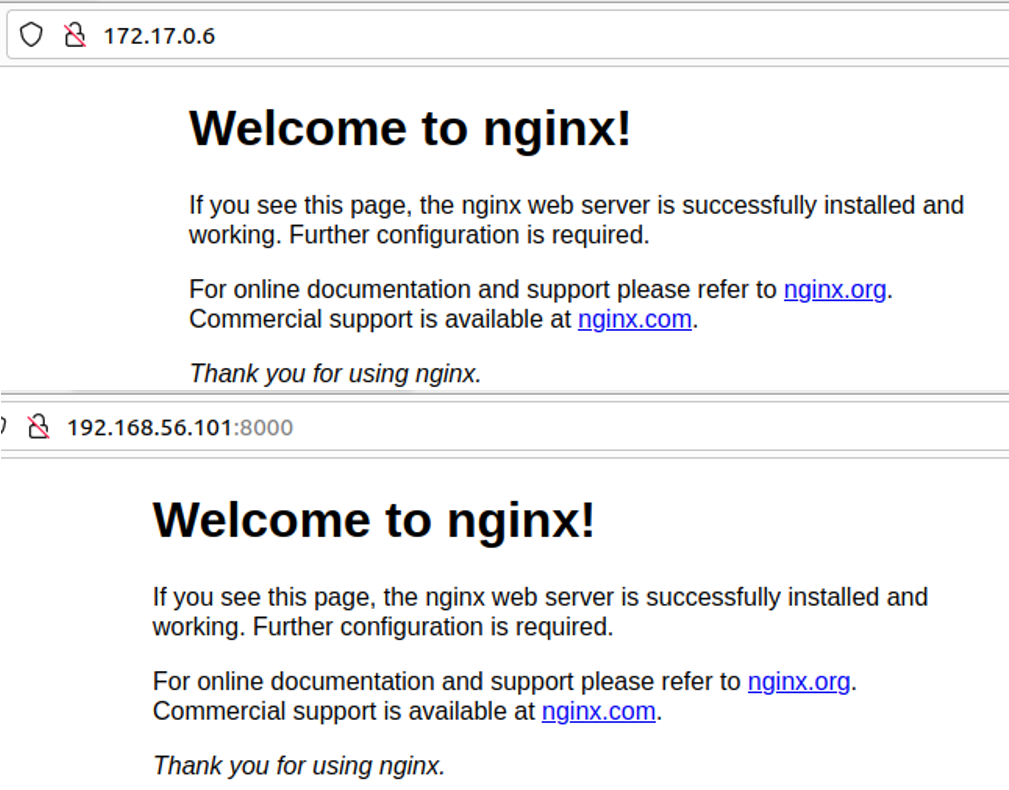
위와 같이 가상머신(내부)에서는 두 ip 모두 같은 결과를 출력해내는 것을 확인할 수 있다.
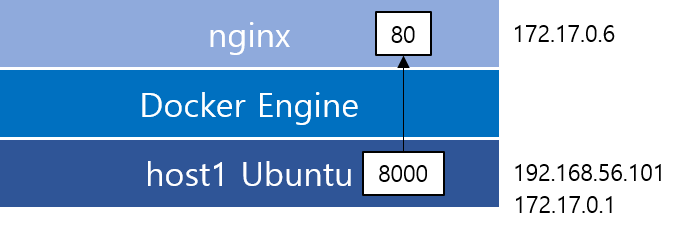
위와 같은 구조이므로 윈도우 입장에서는 host1 Ubuntu를 거쳐야만 한다.
192.68.56.101:8000 → 172.17.0.6:80으로 포트포워딩을 했기 때문에 위와 같이 접속이 가능하다.
외부에서는 172.17.0.6으로 바로 접속하는 것이 불가능하다.
7. index.html을 생성해 nginx에 적용해보기
nginx의 메인페이지를 변경하기 위해 다음과 같은 작업을 수행한다.
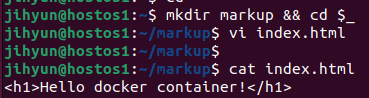
작업을 편리하게 하기 위해 위와 같이 markup 디렉터리 생성 후 index.html 파일을 생성해준다.
nginx 서버는 /usr/share/nginx/html/ 경로에 해당 파일을 저장한다.
$ docker cp 파일명 컨테이너명:/usr/share/nginx/html/index.html
호스트에서 컨테이너로 파일을 보내는 방법은 바인드마운트(잘 사용하지 않음), 볼륨마운트 등이 있지만 지금은 복사 명령어로 진행한다.
cp 명령어를 통해 현재 작업폴더에서 복사할 파일을 컨테이너의 해당 경로로 복사해준다.
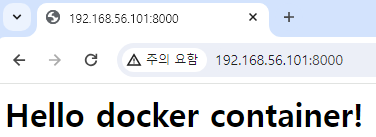
서버에 다시 접속해보면 위와 같이 입력한 내용대로 잘 변경되는 것을 확인할 수 있다.
8. 갱신한 nginx 이미지 만들어보기
Dockerfile을 생성하여 직접 이미지를 만들어볼 수 있다.
FROM nginx:1.25.3-alpine # 어떤 이미지 위에 갱신할 파일을 올릴지
COPY index.html /usr/share/nginx/html/index.html # 작업중인 nginx 서버에 파일 갱신
EXPOSE 80 # 80번 포트 노출
CMD ["nginx", "-g", "daemon off;"] # nginx -g daemon off; 구문 실행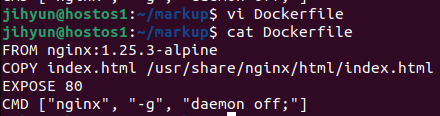
위와 같이 도커파일을 생성해준다.
$ docker build -t 이미지명(지정하기):버전명(지정하기) .복사할 파일인 index.html과 Dockerfile을 같은 경로에 둔 후 위 명령어를 사용하면 먼저 로컬에 이미지를 설치해준다.
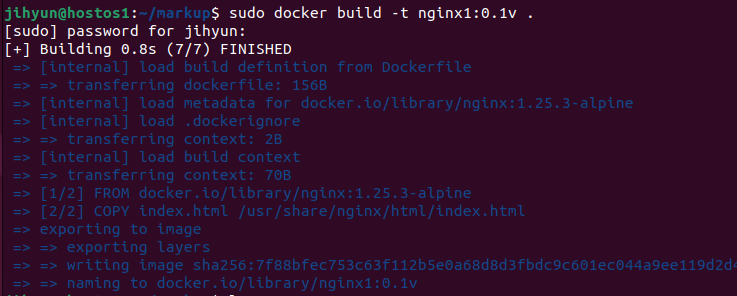

위와 같이 로컬에 이미지가 잘 생성된 것을 확인할 수 있다.

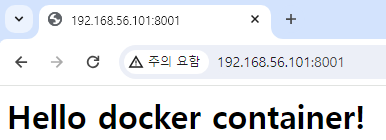
run으로 실행한 후 해당 포트로 접속해보면 위와 같이 잘 작동하는 것을 확인할 수 있다.
추후에는 dockerhub와 같은 원격 레포지토리에 업로드까지 하면 외부에서도 마음대로 받아서 사용이 가능하다.
9. MySQL 컨테이너 생성 및 파라미터 전달 실습
$ docker pull mysql:5.7-debian먼저, 위와 같이 mysql 이미지를 받아준다. MySQL은 환경변수가 중요하기 때문에 공식 문서를 보고 진행하는 것이 좋다.
$ docker run -it -e MYSQL_ROOT_PASSWORD=초기비번 mysql:5.7-debian /bin/bash위와 같이 ROOT 비번을 -e 옵션으로 환경변수 처리하여 넘겨줘야 작동한다.

위와 같이 루트계정 제어창으로 잘 넘어간 것을 확인할 수 있다.
버전 확인


위와 같이 MySQL 데몬을 기동하여 외부에서 접속 가능한 상태로 만들어준다. (MySQL 서버 실행)
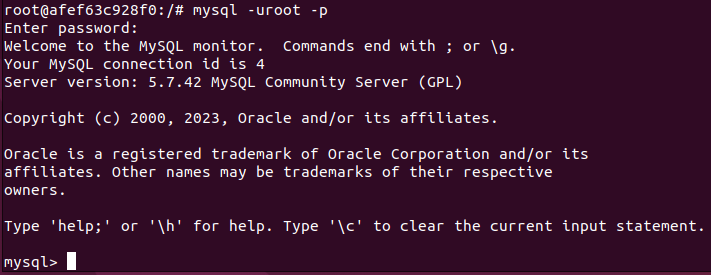
아까 설정했던 비밀번호를 입력하면 위와 같이 mysql이 잘 실행되는 것을 확인할 수 있다.
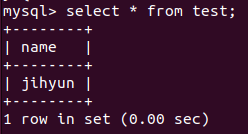
위와 같이 테이블 조회, 생성 등 데이터 입출력이 모두 가능하다.

exit하면 위와 같이 mysql이 잘 종료되어 있는 것을 확인할 수 있다.
이후 docker run을 하면 새로운 컨테이너가 생성되기 때문에 다시 실행할 때는 docker start로 해줘야 한다.
$ docker start 컨테이너명
$ docker exec -it 컨테이너명 bashstart로 실행한 경우 exec로 해당 인스턴스의 bash 창으로 진입해야 다시 명령을 내릴 수 있다.


이와 같이 잘 접속이 된다.
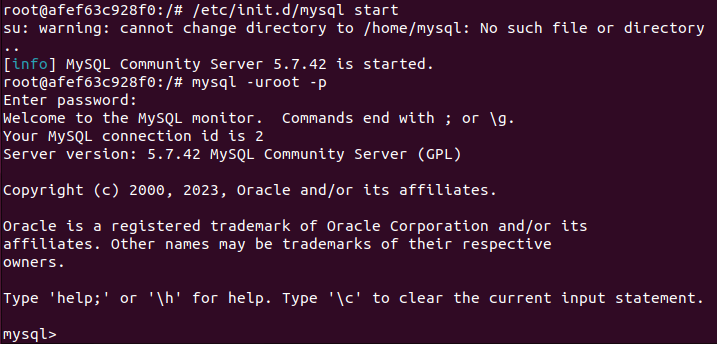
또한, MySQL 데몬은 새로 켤 때마다 실행시켜주어야 한다.
10. 컨테이너로 띄운 DB엔진 워크벤치로 다뤄보기
$ docker run --name mariadb -e MYSQL_ROOT_PASSWORD=비번 -d -e MARIADB_DATABASE=item -p 3306:3306 mariadb:10.2

마리아디비를 실행하고 item이라는 데이터베이스도 같이 생성하라는 의미이다.
워크벤치는 오라클 사이트에서 다운받거나 DBeaver 같은 오픈소스를 사용해도 된다.
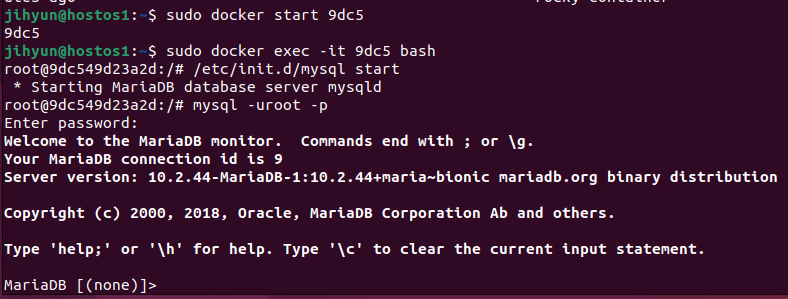
위와 같이 MariaDB에 잘 접속된 것을 확인할 수 있다.
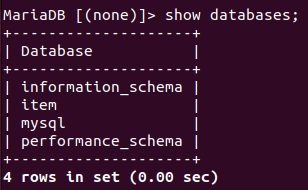
초기에 생성했던 item이라는 데이터베이스도 잘 들어있는 것을 확인할 수 있다.
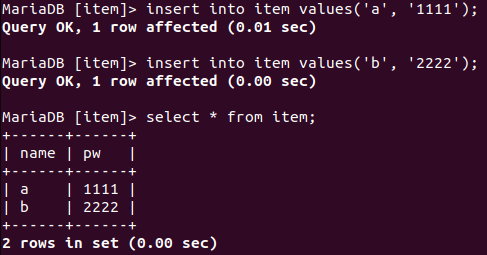
위와 같이 테이블 생성, 입력, 조회 모두 가능하다.
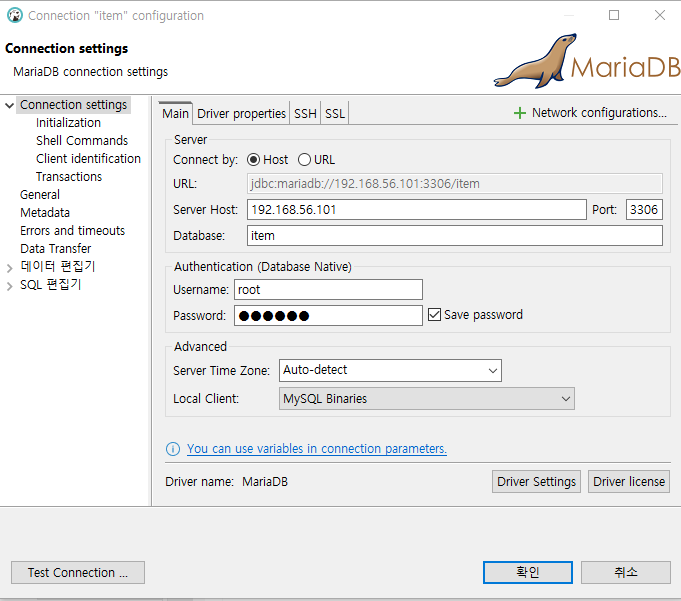
워크벤치에 접속하여 아까 만든 DB 등이 있는지 조회할 수 있다.
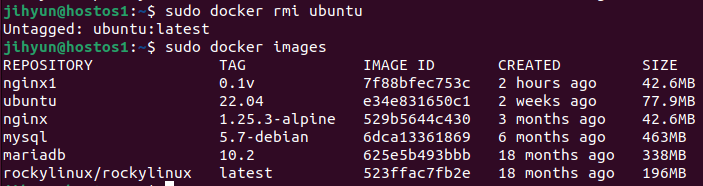
이미지 삭제 시 rmi 명령어를 이용한다.
'네트워크캠퍼스 > DOCKER' 카테고리의 다른 글
| 도커 이미지 구조 (0) | 2024.01.30 |
|---|---|
| Portainer를 이용해 GUI로 컨테이너 관리 (0) | 2024.01.26 |
| Play with Docker (0) | 2024.01.23 |
| 로컬 환경 설정 (virtualbox + ubuntuos) (0) | 2024.01.22 |
| 도커의 기반 기술과 이론적 이해 (0) | 2024.01.19 |