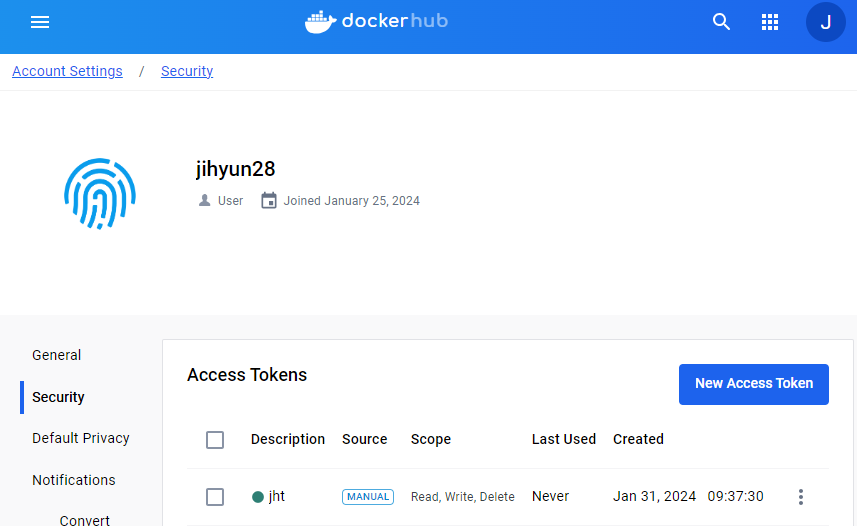
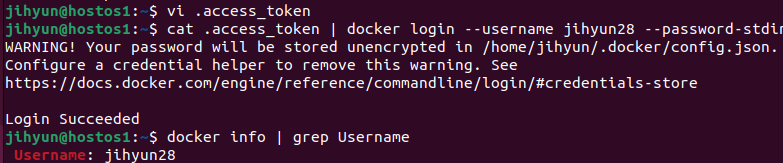
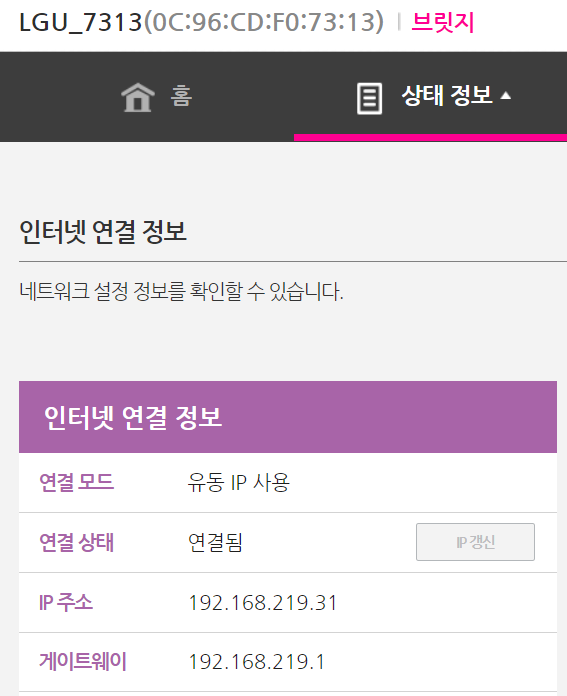
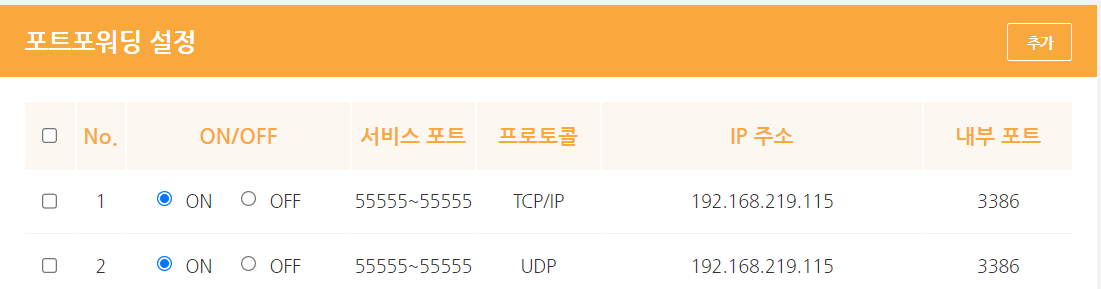
※ LXC로부터 시작된 도커의 컨테이너 가상화 기술은 현재는 도커엔진이라는 자체 스펙으로 바뀌었지만, 근간은 여전히 LXC에 있다.
1. 컨테이너 내부 측정
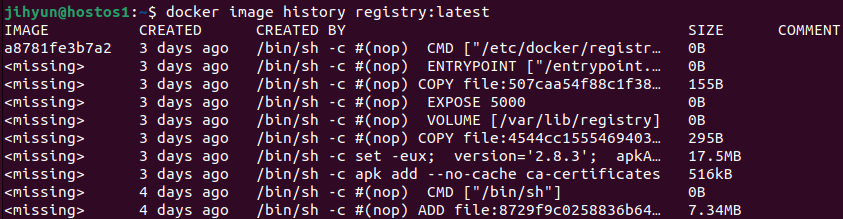
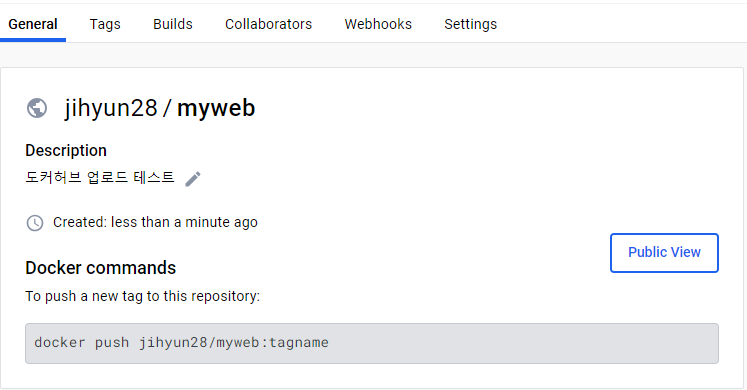
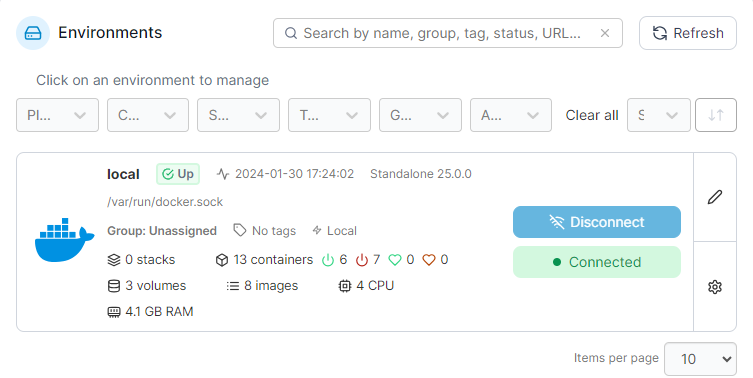
처음 가상머신 생성 시 위와 같이 도커가 깔리는 드라이버와 OS가 깔리는 드라이버로 나누었다.
/var라는 폴더에 이미지라는 특정 OS와 특정 프로그램이 패키징된 스냅샷을 찍어두고 프로세스를 띄우는 방식으로 진행한다.
이 때 layer라는 개념을 통해 각각의 구성 요소를 조합하게 되고, 이미지 레이어는 Read Only 레이어와 Read, Write가 가능한 컨테이너 레이어가 있다.
이미지를 이용해 띄운 컨테이너는 내부적으로 OS가 먼저 실행되며 PID 1번 부여받음, 추가로 네트워크, CPU, 메모리, 디스크 등도 할당받음
이는 리눅스로 수행할 수도 있지만 편의성 증대를 위해 도커라는 기술을 활용한다.

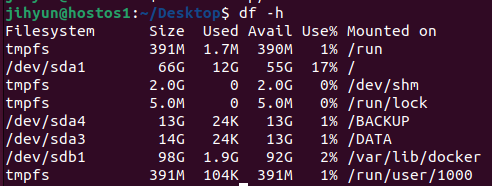
내부 구조를 가져오기 위해 먼저 pull과 run을 이용하여 ubuntu 14.04 버전의 bash를 띄워준다.
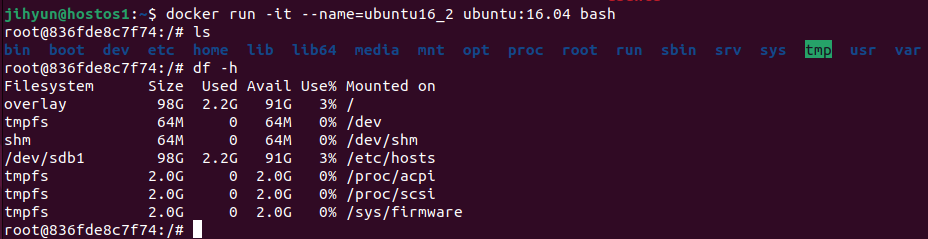
ls로 조회해보면 시스템 영역에서 사용할법한 디렉터리들(opt, proc, root, run sbin 등)이 위치하는 것을 확인할 수 있다.
이를 chroot 혹은 pivot_root라고 부른다. → root file system을 구성하게 도와주고, 이를 통해 독립성이 보장된다.
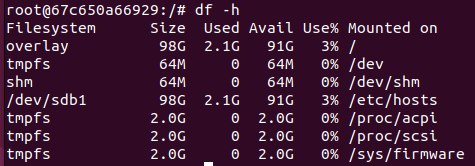
컨테이너 안에서 조회해보면 위와 같이 디바이스의 사용량이나 가용 자원 등에 대해 나오는데, 특이점은 host docker가 설치된 영역인 /dev/sdb1이 그대로 공유되는 것을 볼 수 있다.
pivot_root와 mount namespace가 위 사례이다.
mount namespace : 장비를 mount시키는 것처럼 가동하는 기술
UTS namespace : 컨테이너 아이디와 호스트네임을 동기화시키는 작업

모든 OS는 호스트네임을 가지고, 컨테이너가 생성되면 container id가 부여된다. 해당 ID가 hostname으로 사용된다.

해당 프로세스가 작업을 수행하는데 필요한 것들을 격리시키는 기술인 PID 혹은 IPC namespace라는 기술이 적용된 것을 볼 수 있다.
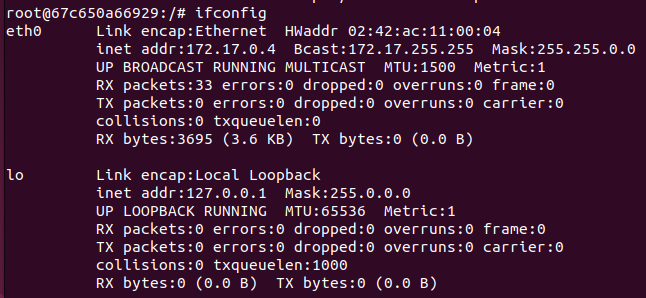
ifconfig로 확인해보면 위와 같이 eth0에 내부 IP가 할당된 것을 볼 수 있고, 이를 network namespace라고 부른다.
위와 같은 여러 기술이 어우려져 host와는 격리된 환경에서 컨테이너가 하나의 프로세스로 동작한다.
2. 컨테이너 격리 기술
| chroot | 프로세스의 루트 디렉토리를 변경, 격리하여 가상의 루트 디렉토리 배정 |
| pivot root | 루트 파일시스템을 변경, 컨테이너가 전용 루트 파일시스템을 가지도록 함 |
| mount namespace | namespace 내에 파일 시스템 트리 구성 |
| uts namespace | host와 다른 별개의 hostname을 가지도록 함 |
| pid namespace | pid와 프로세스 분리 (systemd와 분리, 우분투의 1번 프로세스인데 잡히지 않음) |
| network namespace | 네트워크 리소스 할당 (ip, port, route table, ethernet 등) |
| ipc namespace | 전용 process table 보유 |
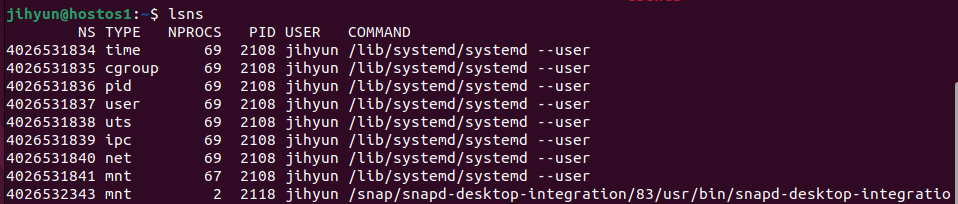
위와 같이 격리된 namespace 목록은 위와 같이 lsns 명령어로 조회할 수 있다.
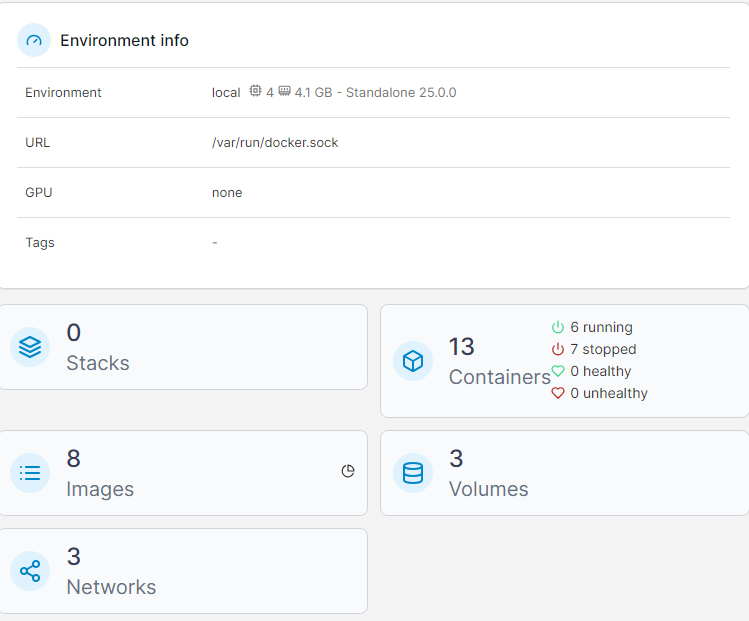
3. 컨테이너의 라이프사이클
① create : image의 스냅샷으로 /var/lib/docker 영역 내에 컨테이너 생성
② start : process 영역에 컨테이너를 생성하여 실행 상태로 만들어줌
③ stop : process 영역에 컨테이너를 제거하여 종료 상태로 만들어줌
④ rm : create로 생성된 스냅샷 삭제
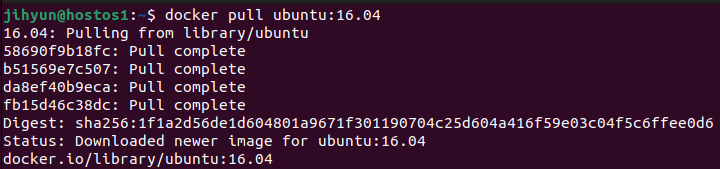

먼저, pull로 ubuntu:16.04 버전을 받아온다.

create 명령어로 새로운 컨테이너를 생성하고 조회해보면 위와 같이 Created 상태의 컨테이너가 만들어진 것을 확인할 수 있다.
Created 상태는 스냅샷을 만들어두기만 하고 프로세스로 가동은 하지 않은 상태이다.

프로세스로 올려서 실행시키기 위해 start 명령을 이용하고 확인해보면 위와 같이 Up 상태로 바뀐 것을 확인할 수 있다.

stop 명령어를 이용하고 확인해보면 위와 같이 Exited 상태로 바뀐 것을 확인할 수 있다.
Exited 상태는 프로세스로 구동만 안하고 있을 뿐 구동 준비는 된 상태이기 때문에 언제든 다시 start가 가능하다.

rm 명령어로 컨테이너를 삭제해주면 위와 같이 아무것도 조회되지 않는 것을 확인할 수 있다.
create와 start를 합친 run 명령어를 이용하면 위와 같이 바로 bash 창으로 들어가는 것이 가능하다.
# apt update
# apt -y install net-tools각 컨테이너들은 격리환경이기 때문에 필요한 업데이트나 의존성 설정은 처음부터 해줘야 한다.
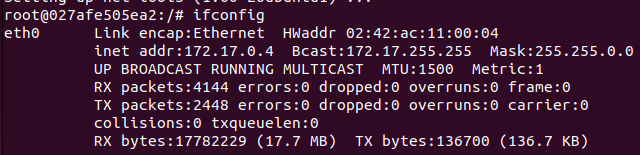
ifconfig로 확인하면 위와 같이 잘 출력되는 것을 볼 수 있다.
4. 컨테이너 내부 구조
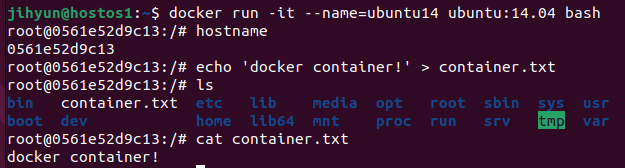
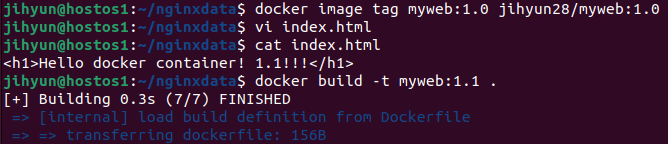
먼저, ubuntu14.04 버전의 컨테이너를 띄운 후 위와 같은 작업들을 수행했다.

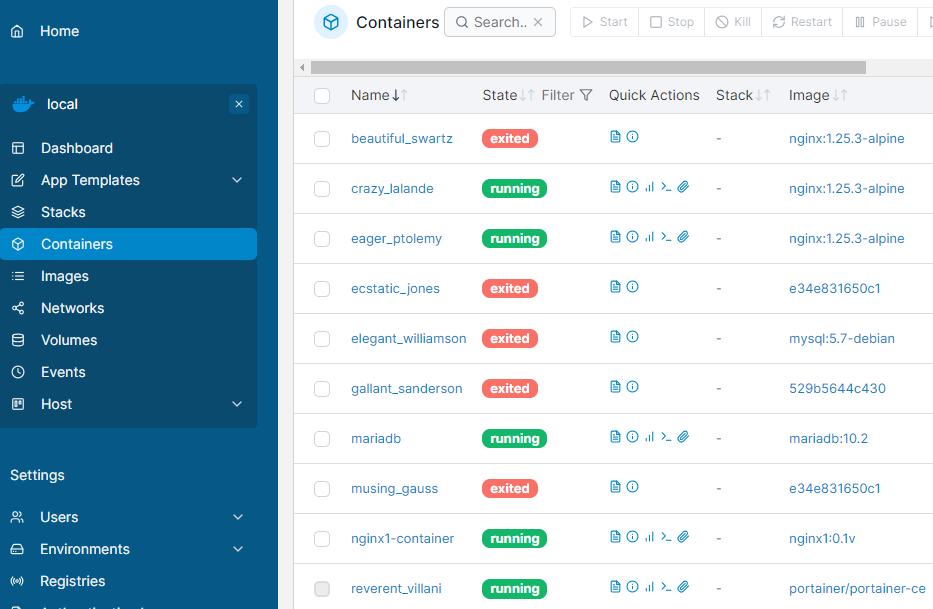
위와 같이 프로세스를 조회해보면 도커 컨테이너가 프로세스로 잡혀있는 것을 확인할 수 있다.
※ 스냅샷(이미지)은 Read only이지만, 컨테이너(프로세스)는 Read, Write가 가능하다.

root 권한 상태로 변경 후 find 명령어로 container.txt를 찾아보면 위와 같은 결과를 확인할 수 있다.

merged 경로로 이동한 후 ls를 해보면 컨테이너 내부의 파일 구성이 그대로 보이는 것을 확인할 수 있다.
즉, 컨테이너 내부는 사실 overlay2라는 스토리지 영역에 포함된 컨테이너 아이디 폴더에 종속되어 있는 파일들의 집합이라는 것을 알 수 있다.

다른 터미널에서 조회해보면 위와 같이 같은 내용이 나오는 것을 확인할 수 있다.


루트권한에서 a라는 파일을 생성한 후 다른 터미널에서 컨테이너 내부를 조회하면 잘 동기화되는 것을 확인할 수 있다.
☆ 즉, 컨테이너 내부에서 생성된 정보는 container layer + snapshot 영역에 저장된다.
5. 컨테이너 운영 명령어
먼저, 컨테이너 운영을 살펴보기 위한 노트 웹서버를 구축하기 위해 다음과 같은 파일을 작성해준다.
- app.js
const http = require('http');
const server = http.createServer().listen(5678);
server.on('request', (req, res) => {
console.log('request');
res.write("HostName: " + process.env.HOSTNAME + "\n");
res.end();
});
server.on('connection', (socket) => {
console.log("connected.");
});
- Dockerfile
FROM node:20-alpine3.17 // 어떤 os와 프레임워크 위에서 돌릴지
RUN apk add --no-cache tini curl // 알파인 리눅스이므로 apk로 구동
WORKDIR /app // /app이라는 경로 생성 후 cd /app 실행
COPY app.js . // Dockerfile과 같은 경로의 app.js를 현재경로에 복사
EXPOSE 5678 // 포트바인딩 시 컨테이너 측의 노출포트가 5678
ENTRYPOINT ["/sbin/tini", "--"] // 내부적으로 app.js를 실행해주는 명령어
CMD ["node", "app.js"] // (ENTRYPOINT와 CMD)

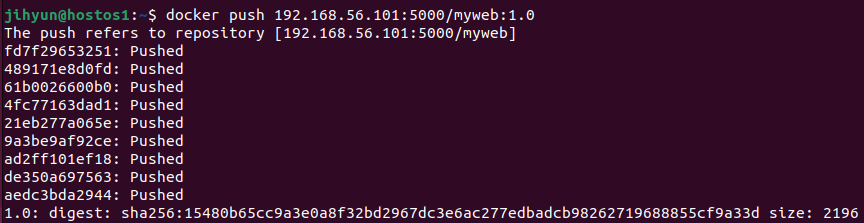
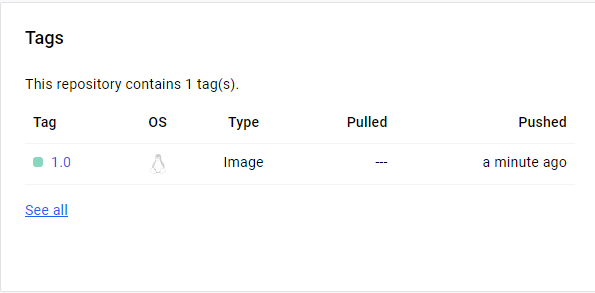
위 명령어로 이미지를 생성한다.
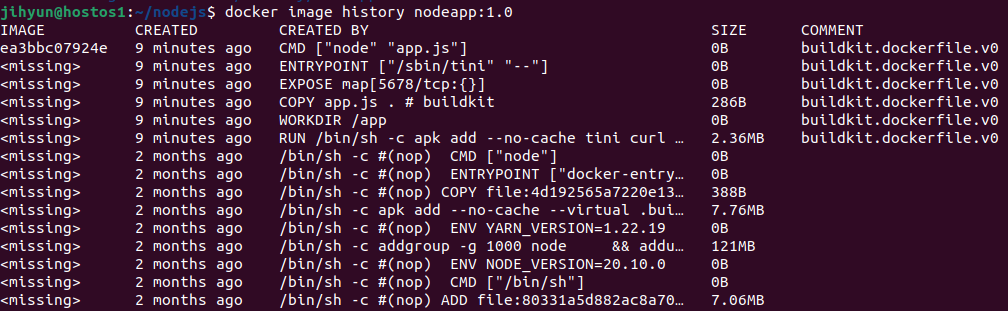
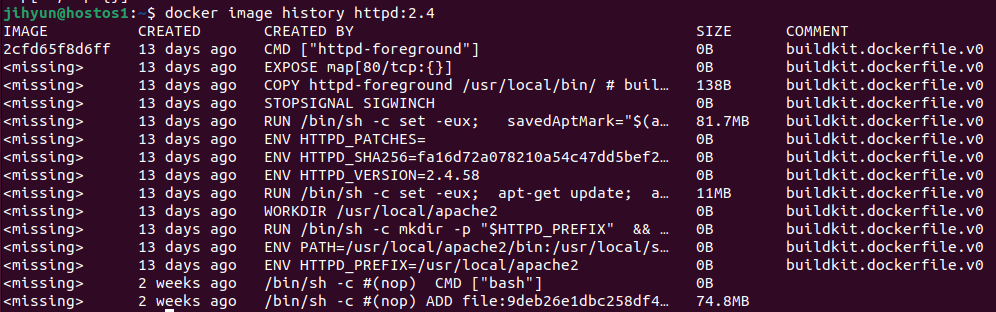
위와 같이 history 명령어로 nodeapp의 내용을 확인해볼 수 있다.

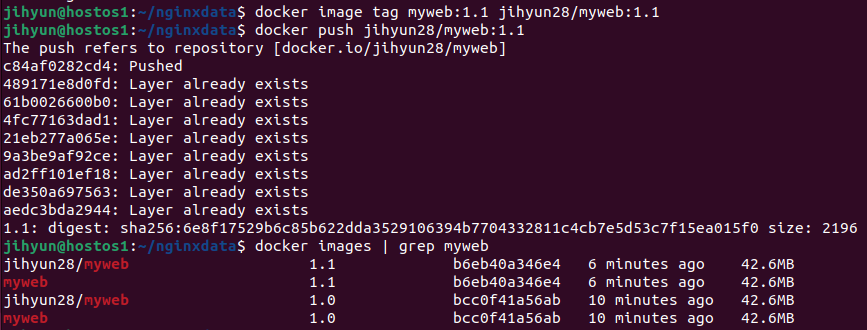
run 명령어로 컨테이너를 실행하고, 조회해보면 위와 같이 잘 띄워진 것을 확인할 수 있다.
-h 옵션은 hostname을 nodeapp으로 구성하겠다는 의미이다. 해당 태그를 주지 않으면 컨테이너 아이디가 hostname으로 부여된다.
※ 세부옵션
| --env | 컨테이너의 환경변수 지정 |
| -d --detach=true |
백그라운드 실행모드 활성화, 컨테이너 아이디 등록 |
| -t | TTY 할당 (bash창 열어주기) |
| -i --interactive |
대화식 모드 열기 (컨테이너 내부에 명령어 주고받기) |
| --name | 실행되는 컨테이너에 이름 부여 (미지정 시 랜덤한 2단어 조합명으로 부여) |
| --rm | 컨테이너 종료 시 자동으로 컨테이너 제거 (stop 시 삭제) |
| --restart | 컨테이너 종료 시 적ㅈ용할 재시작 정책 지정 (no, on-failure, on-failure:n(횟수), always) |
| -v --volume=호스트경로:컨테이너경로 |
볼륨설정 (볼륨마운트) |
| -h | 컨테이너의 호스트명 지정 (미지정 시 컨테이너 아이디를 호스트명으로 등록) |
| -p 호스트포트:컨테이너포트 --publish |
호스트 포트와 컨테이너 포트를 바인딩 |
| -P --publish-all=true|false |
컨테이너 내부의 EXPOSE 포트를 랜덤포트와 바인딩 |
| --workdir -w |
컨테이너 내부의 작업 경로 (디렉터리) |

docker top 명령어를 이용하여 컨테이너에서 현재 실행 중인 프로세스의 상태를 볼 수 있다.

docker port 명령어를 이용하여 포트정보를 알 수 있고, IPv4와 IPv6에 대한 정보가 모두 나온다.

위 명령어를 이용해 docker-proxy라는 대리포트 값을 조회할 수 있다.

위에서 얻은 프록시 값으로 위 명령어 입력 시 해당 포트바인딩 명령어의 정보가 저장된 위치가 나온다.


docker stats 명령어로 실시간으로 어떻게 자원을 소비하고 있는지 확인할 수 있다.
해당 컨테이너로 curl이나 브라우저 접속을 유도하면 갑자기 사용량이 증가하는 것을 관찰할 수 있다.
컨테이너명을 여러개 적으면 동시에 조회도 가능하며 흐름에 따른 갱신을 보고싶지 않다면 --no-stream 옵션을 추가하면 된다.
6. 모니터링용 이미지 및 컨테이너로 상태 감시
1) cadvisor
→ docker stats로도 상태를 감시할 수 있지만 좀 더 전문적으로 감시할 수 있는 툴
→ 도커허브가 아닌 gcr에 올라와 있기 때문에 아래와 같은 명령어들로 볼륨마운트를 해야만 볼 수 있다.
$ docker run \
--restart=always \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys/fs/cgroup:/sys/fs/cgroup:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8765:8080 \
--detach=true \
--name=cadvisor \
--privileged \
--device=/dev/kmsg \
gcr.io/cadvisor/cadvisor:latest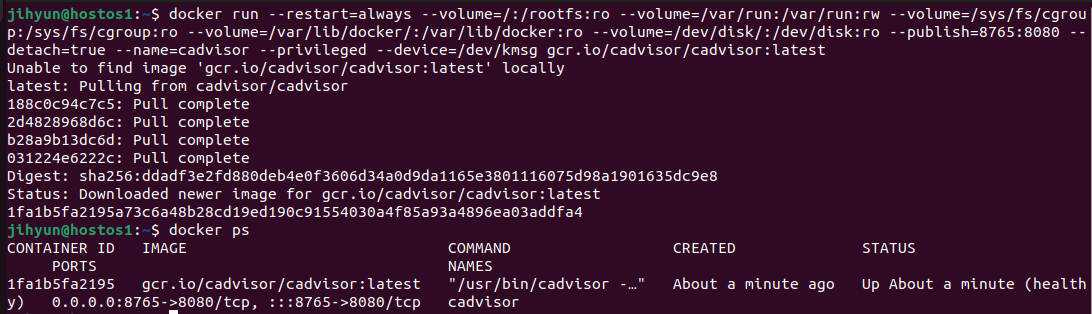
위와 같이 이미지를 받은 후 조회해보면 컨테이너가 잘 띄워진 것을 확인할 수 있다.

해당 IP와 포트로 접속해보면 위와 같이 잘 접속된다.
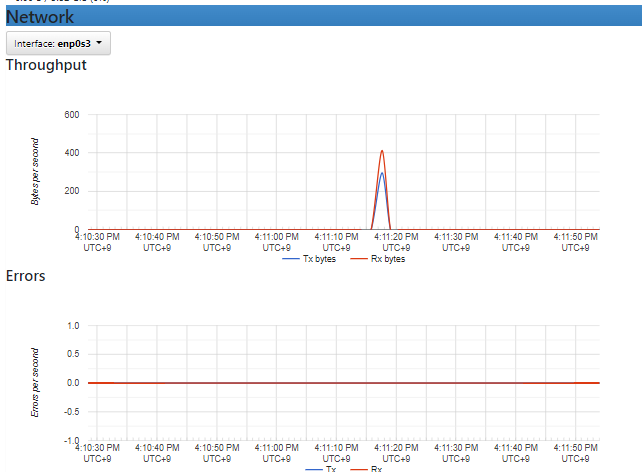
위와 같이 매트릭 형태로 실시간 트래픽들을 확인할 수 있다.
리눅스에서 반복문 수행 시 헬스체크를 수행하도록 할 수 있다.
※ 헬스체크 : 서버의 가동 여부를 지속적으로 확인하는 행위
$ while true; do curl 노드서버주소; sleep 초단위; done위와 같은 반복문 수행 시 sleep으로 딜레이를 주기 때문에 해당 초마다 한 번씩 노드서버에 접속하게 된다.
console.log()를 이용하여 nodeapp에 지속적으로 요청을 넣어 찍히는 log를 확인할 수 있다.
7. cp 명령어로 컨테이너 내부에 호스트 파일 복사하기
간단한 파일 전송 시에는 볼륨마운트 대신 cp 명령어를 이용하여 넘기기도 한다.
$ docker cp 호스트파일명 컨테이너명:경로와파일명
'네트워크캠퍼스 > DOCKER' 카테고리의 다른 글
| 도커 네트워크 (0) | 2024.02.05 |
|---|---|
| 아틸러리를 활용한 스트레스 테스트 (0) | 2024.02.05 |
| 도커 레지스트리 구축 (0) | 2024.01.31 |
| 도커 이미지 구조 (0) | 2024.01.30 |
| Portainer를 이용해 GUI로 컨테이너 관리 (0) | 2024.01.26 |