1. 네트워크 전반에 대한 이해
1) 누구를 위한 네트워크인가?
ⓛ 누가 사용하는가?
- 일반 사용자용 : 네트워크에 개인으로 접속
- 기업용 : 회사원, 교내 네트워크 등
② 어디에서 사용하는가?
- 가정용 : 네트워크 인프라 부분에 광 회선이나 CATV 등의 액세스 회선을 이용해 사용 → 전자우편, 웹브라우저 등
- 기업용 : 네트워크 인프라 부분에 인터넷 회선만이 아니라 사내 전용 내선 전화망, IP 네트워크망 존재, 거점 간 통신
→ 고성능과 신뢰성이 요구, 고가, 보안 측면의 고려 필요, 법인으로서의 사회성 요구
- 가정용과 기업용의 차이 : 사용자가 이용하는 애플리케이션의 종류, 네트워크의 물리적 규모
③ 서비스 프로바이더용 네트워크 (=통신 캐리어 사업자용 네트워크)
- 통신 사업자나 ISP의 네트워크 ex) KT, SKT, LG U+
- 네트워크 형태에서 보면 WAN의 부분이 됨 → WAN 회선을 법인 기업용으로 제공하기 위해 네트워크 구성
- 대표적인 서비스로 IP-VPN이나 광역 네트워크가 있음
- 규모가 크고 고도의 성능과 높은 신뢰성 요구됨
∴ 기업에 통신회선 서비스(WAN)를 제공하기 위해 통신 사업자나 ISP에 의해 구축됨
2) 네트워크의 형태
ⓛ LAN과 WAN
- LAN : 회사 건물 내부나 가정 내부의 비교적 작은 범위의 네트워크
- WAN : 멀리 떨어진 LAN 간을 이어주기 위한 것, 보다 광범위하고 규모가 큰 네트워크
KT나 SKT의 통신 사업자망을 사용하여 구축된 네트워크
- MAN : LAN과 WAN의 중간으로 특정 지역을 담당 ex) 도시형 네트워크(CATV) 등
② 인트라넷(=사내 인트라넷)
- 독립적인 사내 네트워크
- 인터넷 기술을 기업 내 인터넷이 도입하고 정보 공유나 업무 지원에 활용하는 것을 목적으로 구축된 시스템
- 일반적으로 기밀성이 높은 업무 애플리케이션이 사내 인트라넷으로 구성되어 운용됨
3) 네트워크의 일반적인 구성
ⓛ 네트워크의 전체 구성 (기업의 예시)
- 대규모 거점 : 본사와 지사 ex) 서울, 대전, 부산
- 중규모 거점 : 지점 ex) 대구, 울산, 세종, 광주
- 소규모 거점 : 나머지 지역
② 소규모 거점 네트워크 : 세 구역 이내의 단순한 네트워크

- LAN과 사용자 단말 : 사용자가 작성한 데이터는 OSI나 TCP/IP 프로토콜의 규칙에 따라 네트워크를 사이에 두고 통신
- WAN 회선 : 주로 인터넷 VPN 사용 → 안정성보다 비용 중시
- 스위치 : 레이어2 스위치(L2 스위치)로 구성되는 경우가 대부분 → 단순한 네트워크
- 라우터 : 반대쪽 라우터와 가상 네트워크의 경로 확립, 외부에서 들어오는 부정 패킷에 대한 방파제 역할
- 보안 : 방화벽 → 안팎으로부터의 패킷에 대해 통과를 허가/거부하는 역할, 소규모 거점에서는 라우터의 기능(패킷 필터링 기능) 안에서 작동시키는 경우가 대부분
- IP 전화 : 소규모 거점에서는 IP 전화기만 설치됨
- 무선 LAN : 무선 LAN 클라이언트(무선 LAN 어댑터를 탑재한 사용자 PC)와 무선 LAN 액세스포인트로 구성
③ 중규모 거점 네트워크 : 복수 구역의 이중화 구성을 고려한 네트워크

- WAN 회선 : 네트워크 장애 방지를 위해 이중화 구성(네트워크 장애를 고려한 예비용 구성)을 고려
- 스위치 : 네트워크 구성을 유연하게 변경할 수 있는 VLAN 기능을 가진 레이어2 스위치 필요, 레이어3 스위치를 설치하여 다른 네트워크 간 통신이 가능하도록 함
- 라우터
- 하나의 라우터로 복수의 WAN 회선을 보유 : 라우터 자체에 장애 발생 시 WAN으로의 전체 통신 불가능
- 복수의 라우터로 각각의 WAN 회선을 보유 : 회선이나 라우터 자체의 장애 발생 시에도 운용에 영향 X
④ 대규모 거점 네트워크 : 여러 구역의 모든 부분에 대한 이중화를 고려한 네트워크

- LAN과 사용자 단말 : 전용 서버룸은 존재하지만, 최근에는 데이터 센터가 그 기능을 가짐
- 스위치 : 대규모 거점에서는 스위치의 이중화도 고려해야 함
- 보안(방화벽) : 네트워크상에 전용 기기로서 도입됨
- IP 전화 : IP 전화기는 물론 음성 서버도 설치됨
※ 음성 서버 : 음성 네트워크 전체의 전화번호와 IP 주소의 대응표 관리, IP 전화기 간의 통화 중계 담당
- 무선 LAN : 무선 LAN 컨트롤러 도입 → 설치 장소 관리, 무선 LAN 액세스포인트 간의 전파 간섭에 대한 대비
2. LAN 초보 입문
1) OSI 기본 참조 모델
① 프로토콜 : 컴퓨터 통신에 필요한 약속을 정한 것
② OSI 기본 참조 모델 : 여러 다른 제조사의 네틍워크 기기 간의 통신이 문제없이 이루어지기 위해 따라야 하는 국제 표준

- 각 계층의 독립성과 전문성을 높여 새로운 기술에 유연히 대응하도록 함
※ PDU(Protocol Data Unit) : OSI 기본 참조 모델 계층별 제어 정보와 데이터에 따라 구성되는 단위
→ 전송계층(세그먼트), 네트워크계층(패킷), 데이터링크계층(프레임)
2) LAN
① LAN의 위치

라우터를 기준으로 LAN과 WAN의 경계가 나뉨
② LAN의 구성요소

- 대부분 이더넷(물리계층, 데이터링크계층에 대한 규격)으로 구성
- LAN 카드 : UTP 케이블을 꽂는 곳, 네트워크 인터페이스 카드(NIC)라고도 함
- UTP 케이블 : 두 개의 동선을 꼬아 만든 것을 1페어로 4페어의 선을 묶은 케이블 → 한쪽은 LAN카드, 다른 한쪽은 스위치에 꽂음
- 다이렉트 케이블 : PC 단말과 스위치 간, 스위치와 라우터 간 접속용으로 사용
- 크로스 케이블 : 스위치 간이나 라우터와 PC 단말을 직접 연결 시 사용
※ 최근에는 구역과 구역을 잇는 백본 부분에 광 케이블을 사용하는 것이 일반적
- LAN 카드나 네트워크 기기는 읽기 전용 메모리(ROM)를 가지고 있어 고유의 주소를 기록 → MAC 주소
③ LAN의 배선
- 바닥 LAN 배선 : 바닥에 깔려있는 카펫을 걷어내면 조립식 패널이 설치되어 있고, 패널 아래에 케이블이 깔려 있음
→ 프리 액세스 영역 : 바닥에 전력, 통신용 배선 및 공기 정화 장치 등의 기기를 수납하는 마루로 배선 작업이 쉬운 구조
- 천장 LAN 배선 : 와이어 프로텍터를 따라 19인치 랙까지 닿을 수 있도록 천장 위에 배선
3) IP 주소
① 네트워크 기기에 주소 할당
- IP 주소 : 데이터를 네트워크 기기나 단말에 보내기 위한 식별 정보 → 라우터를 통한 다른 네트워크와 통신 시 필요
- TCP/IP의 IP 프로토콜로 사용
- 10진수 표기, 32비트로 구성(네트워크 주소 부분 24비트, 호스트 주소 부분 8비트)
- 호스트 주소 부분을 전부 0으로 한 것이 네트워크 주소
- 호스트 주소 개수 계산 시 2를 빼는 이유? 네트워크 주소(0)와 브로드캐스트 주소(255)를 남겨야 하기 때문
② IP 주소의 클래스
- 클래스 A~E까지 5개로 나뉘어져 있고, 사용자에게 할당되는 주소는 클래스 A~C
- 클래스 A : 주소 시작이 1~126
- 맨 앞의 1비트가 0으로 시작
- 네트워크 주소 부분 8비트, 호스트 주소 부분 24비트
- 클래스 B : 주소 시작이 128~191
- 맨 앞의 2비트가 10으로 시작
- 네트워크 주소 부분 16비트, 호스트 주소 부분 16비트
- 클래스 C : 주소 시작이 192~223
- 맨 앞의 3비트가 110으로 시작
- 네트워크 주소 부분 24비트, 호스트 주소 부분 8비트
- 클래스 D : 멀티캐스트용 주소 → 사용자의 주소로 할당 불가
- 클래스 E : 실험용 주소 → 사용자의 주소로 할당 불가
③ 할당할 수 없는 주소
- 네트워크 주소 : 호스트 주소 부분의 비트가 전부 0
- 브로드캐스트 주소 : 호스트 주소 부분의 비트가 전부 1
※ 브로드캐스트 : 네트워크 내의 불특정 다수에게 패킷을 동시에 전달하는 것
→ 통신 상대를 지정할 수 없을 때 사용, 여러 프로토콜이나 애플리케이션을 사용하는 경우에 발생
④ 특수 용도의 주소
- 루프백 주소 : 주소의 시작이 127인 것, 네트워크 상에서 자기 자신을 나타내는 인터페이스 또는 그 주소
→ 루프백 주소용으로 예약되어 있으므로 일반 사용자에게 주소로 할당할 수 없음 (일반적으로 127.0.0.1)
- ping 127.0.0.1 : 자신의 PC의 TCP/IP가 활성화되어 있는지 확인 가능 → 장애 원인 파악에 호라용
⑤ 서브넷마스크 : 클래스에 따른 네트워크 수와 호스트 수의 불균형 해결
- 하나의 네트워크로 수많은 단말을 관리하는 것은 불가능
- IP 주소 클래스의 호스트 주소 부분 중 몇 비트를 서브넷으로 할지 지정
ex) 128.1.64.0/18 : 클래스 B이므로 네트워크 16비트, 호스트 16비트
→ /18이므로 서브넷 부분이 2비트이고, 00 01 10 11 즉 4개의 서브넷으로 관리 가능, 호스트 부분은 14비트가 됨
→ 128.1.0.0 / 128.1.64.0 / 128.1.128.0 / 128.1.192.0, 할당할 수 있는 호스트 주소 개수는 2^14 - 2
- 네트워크가 늘어나면 하나의 서브 네트워크 아래에 할당할 수 있는 주소의 수는 그만큼 줄어든다.
⑥ 공인 주소(조직 외)와 사설 주소(조직 내)
- 공인 주소 : 전 세계 어디서도 중복되지 않도록 IANA라는 단체가 관리
- 사설 주소 : 외부와 접속하지 않는 네트워크는 임의의 주소 사용 가능
- 클래스 A : 10.0.0.0 ~ 10.255.255.255
- 클래스 B : 172.16.0.0 ~ 172.31.255.255
- 클래스 C : 192.168.0.0 ~ 192.168.255.255
- 실제 네트워크 환경에서는 공인 주소와 사설 주소를 변환하는 기능을 가진 라우터나 방화벽 등이 주소 변환 시행
- 소규모의 경우 라우터가 하우팅 기능과 함께 주소 변환을 하기도 함
- 대규모의 경우 전용 방화벽을 통해 주소 변환 역할을 함
4) IPv6
① 개요
- IPv4(32비트)의 주소 고갈 문제에 대처하기 위해 고안
- 128비트로 구성 → 사용 가능한 주소가 무한대에 가까움
② IPv6 주소 표기
- 16비트별로 구분하여 16진수로 적음
- 구분 문자는 :(콜론)
- 네트워크 주소 부분에 해당하는 부분을 프리픽스라고 하여 그 길이를 /의 뒤에 씀
③ IPv6 주소의 생략 기법
- 각 블록의 앞에 연속되는 0은 생략 가능
- 0000은 0으로 표현
- 연속되는 0의 블록은 1회에 한하여 ::로 바꿀 수 있음
3. WAN 초보 입문
1) WAN이란?
① 외부와의 접속
- 멀리 떨어진 LAN이나 내선 전화망을 상호 연결하기 위한 광범위 대규모 네트워크
② 누가 운용, 관리하고 서비스를 제공하는가?
- 국가에 통신 사업자 등록 및 신고를 한 전기 통신 사업자
- 대표적으로 KT, SKT, LGU+
- 사용자는 특정 서비스 요금을 전기 통신 사업자에게 지불하고 WAN 회선을 사용
③ 네트워크의 연속성을 고려한 WAN 구성
- 네트워크의 규모나 사용자가 늘어날수록 네트워크의 연속성을 고려한 WAN 구성이 필요
→ 이중화 구성 : 통상 운용에서 사용하는 회선에 장애 발생 시 백업 회선을 통해 통신 가능
- 통상 운용 WAN : 광역 이더넷망, IP-VPN망 → 보안 측면이나 통신의 신뢰성 고려
- 인터넷 VPN : 비용 측면의 장점을 가졌으나 보안 측면과 통신의 안전성에 대한 불안 요소가 남아있음
2) WAN에서의 등장인물

① 건물 내 장치 (액세스라우터) : WAN에 연결하기 위한 라우터
- LAN과 WAN의 패킷을 전달하는 역할
- 액세스 라우터 = WAN 라우터(기업용) = 브로드밴드 라우터(가정용)
- 소규모 거점용 라우터 : 랙의 작은 공간에 설치 가능, 크기가 작아 장애 발생 시 찾을 수 없는 경우가 발생하므로 잘 관리해야 함
② 회선 종단 장치 : WAN과 LAN의 전송 방식 변환
- 책임 경계를 명확히 하는 것이 중요 (어디까지가 WAN인가? 건물 내 장치의 WAN쪽 인터페이스까지가 WAN)
- 통신 사업자의 WAN 회선을 사내 네트워크에 연결하기 위해서는 종단 장치가 필요
- 대표적인 회선 종단 장치 : ONU(가장 많이 사용), 모뎀, TA, DSU
- ONU(전기 신호와 광 신호 변환) : 광케이블(WAN쪽), UTP케이블(LAN쪽), 라우터
③ 액세스 회선 : WAN의 회선
- WAN의 중계국까지 접속하는 회선 → 통신 사업자로부터 제공
- 대표적인 액세스 회선 : 광 회선, 전용선, CATV(케이블TV)
④ WAN 중계망 : 액세스포인트 사이를 중계
- 고속도로의 인터체인지 역할
3) WAN 회선 서비스
① 통신 사업자가 제공하는 통신망 : 다거점 간 통신에 적합 → 기업용
- IP-VPN망 : 통신 사업자가 자비로 구축한 폐쇄 IP망
- 중규모부터 대규모 거점 네트워크에서 이용
- 보안이 중시되는 네트워크에서 이용
- 통신 품질이 요구되는 네트워크에서 이용
※ 인터넷 VPN : 인터넷 상에서 구현된 VPN → 인터넷망에 가상적인 전용선망을 만들어 내는 기술
- 저렴한 비용으로 구축 가능
- 소규모부터 중규모 거점 네트워크에서 이용
- 다점포에서 이용
- 광역 이더넷망 : 거점 사이는 각 네트워크로 연결되어 있지만, 마치 하나의 LAN처럼 네트워크 구성 가능
- IP 상의 다양한 라우팅 프로토콜 설정 가능
- 라우팅 정보 관리 등 운용면에서 복잡
- 네트워크의 중요도가 높아 고도의 설정이 필요한 환경에 적합
② 인터넷망
- 법인과 일반 사용자가 함께 사용
- 비용 절감을 중시하는 경우에 선택
- 보안 측면에서 취약하므로 각자 보안 대책을 세워야 함
4. 스위치 초보 입문
※ 각 기기의 역할과 기기의 설정을 이해하는 것이 중요하다.
1) 리피터 허브와 브릿지
① CSMA/CD 방식 : 허브가 케이블에 데이터를 보내기 위한 규칙
- 허브(=리피터 허브) : PC나 네트워크 기기 등의 단말에서 LAN 케이블을 한곳에 모아 통신 데이터를 중계하기 위한 기기 → OSI 1계층
- CS(Carrier Sense) : 항상 귀기울인다. → 항상 전송로 상의 모든 신호를 듣고 있어 다른 단말이 전송로를 사용하고 있는지 확인
- MA(Multiiple Access) : 누구라도 송신할 수 있다. → 송신하고 싶은 단말은 통신하지 않는 것이 확인된 모든 단말에 언제든 송신 가능
- CD(Collision Detection) : 충돌을 검출한다. → 충돌 발생 시 데이터가 손실되므로 정상적인 정보를 다시 보내기 위해 충돌을 검출해야 함
② 콜리전 도메인 : CSMA/CD 방식에서 데이터 손실이 발생하는 범위
- 콜리전 도메인 안에서는 한 번에 일대일 통신만 가능 → A가 B에게 송신하는 동안 다른 단말은 데이터 송신 불가
- 2000년대 이후 네트워크 환경 변화로 허브만으로는 액세스 제어 불가 (충돌 문제 발생)
- 하나의 콜리전 도메인 안에 여러 대의 단말이 존재하는 것이 문제 → 콜리전 도메인을 작게 나누어 포함된 단말을 줄이면 될 것
→ 스위치와 브릿지에서 구현 가능 (OSI 2계층)
③ 콜리전 도메인을 분할할 수 있는 브릿지
- 브릿지의 필터링 기능 : 프레임 내의 MAC 주소를 평가하여 그 프레임을 브릿지를 넘어 중계할 것인지 판단하는 기능
→ 네트워크 간의 부릴요한 데이터 송신 억제, 충돌 발생 방지
- 필터링 기능의 구조와 역할
- MAC 주소 테이블을 참조하여 필터링 처리 실시
- MAC 주소 테이블 : 송신측의 MAC 주소, 수신 포트를 연결한 정보
- 네트워크를 넘어가지 못하도록 함
→ 수신한 프레임 중 목적지 MAC 주소가 수신한 포트 자체에 연결되어 있을 경우 의미가 없으므로 프레임 파기
- 트래픽을 정리하고 LAN의 중계 역할을 함
→ 목적지 MAC 주소가 수신 포트 이외의 특정 포트에 연결되어 있을 경우 프레임을 해당 특정 포트에서만 송출
2) 먼저 스위치의 기본을 이해하자
① 허브와 스위치
- 허브 : 장비 자체가 콜리전 도메인
- 가지고 있는 모든 포트에게 데이터 송신
- 수신한 데이터 신호를 전달할 뿐, 일대일 통신만 가능하여 매우 비효율적
- 스위치, 브릿지 : 각 포트가 콜리전 도메인
- 장치 내부에 MAC 주소 테이블을 가져 필터링 처리 가능
- 학습된 MAC 주소의 프레임은 특정 포트에만 송신되고, 다른 포트에는 영향을 주지 않음
② 브릿지에서 스위치로
- 프레임 분석과 전송 처리를 브릿지는 소프트웨어에서, 스위치는 하드웨어에서 함에 따라 큰 성능 차이 발생
- 스위치 : 전용 반도체 칩인 ASIC으로 프레임 처리 → 처리속도 빠름
③ 스위치의 포인트
- 레이어2 스위치 : 단말이 송신한 프레임을 받으면 그 프레임에 쓰여 있는 목적지(MAC주소)를 조사하여(MAC주소 테이블 정보 비교) 그 목적지가 접속되어 있는 포트에만 프레임 전송
- 접속하고 있는 단말의 MAC 주소나 접속 포트 등의 정보를 자동 학습하고 MAC 주소 테이블에 저장하여 적절한 포트에 프레임 전송
- 각 포트는 전이중 통신 → 송신과 수신이 동시에 이루어짐
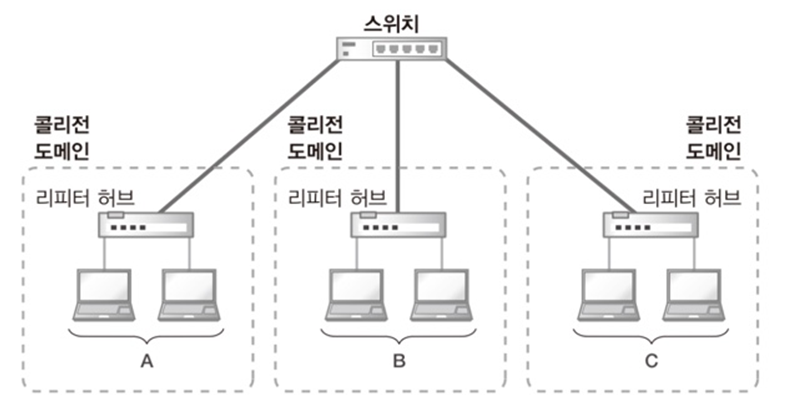
위와 같이 스위치를 사용하면 그룹별로 콜리전 도메인이 분할되어 A 내에서 통신이 이루어질 때 B, C 내에서도 통신이 가능하다.
- 초기 스위치는 장치 자체가 브로드캐스트 도메인
- 목적지 MAC주소가 브로드캐스트 주소(모든 단말을 나타냄)로 되어 있는 브로드캐스트 프레임에 대해서는 모든 포트로 전송
- L2 스위치에서는 스위치 전체가 하나의 브로드캐스트 도메인
- MAC 주소 학습 프로세스
- 스위치 가동 직후에는 MAC 주소테이블에 주소 등록 X
- 데이터가 들어오면 프레임의 출발지 MAC 주소가 MAC 주소 테이블에 등록되어 있는지 확인 (등록되지 않았다면 등록)
- 프레임의 목적지 MAC 주소가 MAC 주소 테이블에 등록되어 있는지 확인
(등록되어 있다면 해당 포트에만, 등록되지 않았다면 모든 포트에 프레임 전송)
3) 조직개편, 당신이라면 어떻게 처리할까? (VLAN)
① VLAN과 브로드캐스트 도메인
- VLAN : 하나의 물리적인 네트워크를 복수의 논리적인 네트워크로 분할하는 기술 → 브로드캐스트 도메인 분할 가능
- 브로드캐스트 도메인 : 브로드캐스트 프레임이 도달하는 범위로 라우터를 넘지 않고 직접 통신할 수 있는 범위
- VLAN의 장점
- 네트워크의 구성을 간단히 변경할 수 있음
- 조직에 맞춰 네트워크를 분할함으로써 보안을 강화할 수 있음
- 브로드캐스트에 의한 네트워크 대역폭 소비를 줄일 수 있음
- 포트 VLAN (=정적 VLAN) : 각각의 포트를 어떤 VLAN에 소속시킬지 고정적으로 설정
- 동적 VLAN : 스위치 포트에 접속한 사용자의 정보를 보고 VLAN을 동적으로 설정
② 트렁크 링크로 하나의 케이블에 여러 VLAN 프레임을 사용
- 트렁크 링크 : 여러 VLAN의 트래픽을 전송하기 위한 스위치 간 접속 전용 링크
- 태그 : 트렁크 링크를 통과시키는 프레임에 들어 있는 해당 프레임이 속해 있는 VLAN을 식별하기 위한 정보
→ ISL과 IEEE802.1Q라는 두 가지 규격이 있음 (식별 정보 첨가 및 제거)
③ VLAN 간의 통신
- L2 스위치만으로는 같은 VLAN에 속한 단말들만 트렁크 링크를 통한 통신 가능
- 다른 VLAN 호스트 간의 통신을 위해서는 라우팅 기능을 가진 장치 필요 → L3 스위치, 라우터
4) 여러 가지 스위치 종류
① 레이어3 스위치 : IP 기능
- L2스위치 + 라우팅 기능
- 여러 VLAN에 IP 주소를 할당하고 라우팅할 수 있음
- 전용 칩(ASIC)으로 하드웨어 처리가 이루어져 기존 라우터보다 빠른 패킷 전송 가능
② 레이어4~7 스위치 : 네트워크 부하를 분산하는 로드 밸런서
- 로드 밸런서 기능 : 부하분산 기능, 상태 확인 기능, 세션 유지 기능
※ 웹서버에서 응답 속도가 느려졌다는 문제는 다음 두 가지 원인을 생각할 수 있다.
- 네트워크 인프라 전체에 발생한 문제인가? → 1~3계층에서 발생한 문제
- 웹 서버 자체의 문제인가? → 웹서버 자체를 교체하거나 로드밸런서 기술을 도입해야 함
5) 이중화로 네트워크의 신뢰성을 높인다
① 스위치 본체의 이중화 : 운용에서 사용하는 스위치 이외에 예브 스위치를 준비해 두는 운용 방법
- 스위치 본체에 장애 발생 시 : 예비 스위치로 전환, 백업 경로를 통해 통신
- 스위치 포트나 LAN 배선에 장애 발생 시 : 예비 통신 경로로 자동 전환, 백업 경로를 통해 통신
- 이중화 실현 기술 : 스패닝 트리 프로토콜 + BPDU
② 스위치 단일 구성
- 스위치 본체, 포트, LAN 배선 중 장애 발생 시 외부와 구역 간 통신 불가 → 동일한 구역의 사용자 간 통신만 가능
- 이중화에 비해 저렴하지만, 신뢰성이 떨어짐
③ 스패닝 트리 프로토콜을 사용하지 않는 이중화 방법이 메인
- 스패닝 트리 프로토콜 문제점 : 대역의 반이 낭비되고 설계나 운용이 복잡함
- 최근 기업 네트워크에서는 스택 접속 + 링크 어그리게이션의 이중화 기술이 주로 사용됨
- 스택 접속 : 여러 대의 스위치를 논리적으로 한 대의 장체로서 인식하는 기능
- 링크 어그리게이션 : 여러 회선을 묶어 하나의 링크로 만드는 방법
5. 라우터 초보 입문
1) 네트워크 전체에서의 라우터 위치
① 소규모 거점에서의 라우터는 가장 중요한 기기
- 소규모 거점에서의 라우터는 멀티 플레이어 : 네트워크 연결뿐만 아니라 방화벽, VPN 기능까지 담당
② 중/대규모 거점에서의 라우터는 네트워크 간의 다리 역할에 치중
- 다른 네트워크를 연결해 주는 것에 치중, 외부 전용(다른 거점의 네트워크)으로 특화됨
- 내부 전용(거점 내 네트워크)은 L3 스위치가 담당
2) 라우터의 역할과 기본 원리
① 라우터
- WAN과 LAN의 경계선에 위치
- OSI 제 3계층에 해당 → IP 주소를 기반으로 라우팅 처리
※ 브릿지, 스위치 : 물리 주소인 MAC 주소를 기반으로 처리
② 라우팅
- 라우터는 자신이 가지고 있는 라우팅 테이블 상의 정보를 가지고 패킷을 라우팅함
- 라우팅 테이블
- 목적지의 네트워크 주소
- 목적지의 네트워크로 패키을 보내기 위한 자신의 인터페이스
- 목적지의 네트우어크에 패킷을 보낼 때의 다음 라우터 주소
- 목적지의 최적 경로를 선택하기 위한 값
- 정적 라우팅 방식 : 네트워크 관리자가 라우팅 정보를 하나하나 등록하는 방식
- 라우터나 네트워크 전체에 부하를 주지 않음
- 운용 후의 유지보수가 어려움
- 소규모 네트워크에 적합
- 동적 라우팅 방식 : 라우팅 정보를 다른 라우터에서 자동으로 받아오는 방식
- 라우팅 프로토콜(라우터 간에 라우팅 정보를 교환하기 위한 전용 프로토콜) 사용
- 라우터나 네트워크 자체에 부하가 발생
- 대표적인 라우팅 프로토콜 : RIP, OSPF, BGP4 등
③ 라우팅 프로토콜
- 디스턴스 벡터 알고리즘 : 인접한 라우터끼리 라우팅 정보 학습
- 대표적인 프로토콜 : RIP (Routing Information Protocol) : 홉 수가 적은 경로를 제일 짧은 경로로 판단하여 패킷을 중계하는 방법
※ 홉(Hop) : 라우터 한 대를 지나는 것
- RIP 단점 : 최대 15홉 라우터밖에 전송하지 못함 → 대규모 네트워크에서는 적합하지 않음
- 링크 스테이트 알고리즘 : 라우터 자체가 접속해 있는 네트워크에 대한 정보를 특정 범위 내에 있는 모든 라우터에 통지하고, 다른 라우터의 링크 상태를 수신한 라우터는 그 정보를 기반으로 학습하고 라우팅 테이블을 생성
- 대표적인 프로토콜 : OSPF (Open Shortest Path First)
- 네트워크를 계층 구조화하여 서브넷 마스크에 사용할 수 있음 → 대규모 네트워크에 적합
- 링크 정보 데이터베이스를 가지고 각 링크에 할당된 비용에서 최적 경로(링크 비용이 최솟값)를 계산
- 패스 벡터 알고리즘
④ 일치하는 라우팅 정보가 없을 때 할당되는 경로
- 기본 경로 : 라우팅 테이블 내에 일치하는 라우팅 정보가 없을 때 패킷을 파기하지 않고 미리 설정해 둔 경로로 패킷을 보낼 수 있음
⑤ 다른 LAN 간의 접속
- 라우터는 네트워크를 분할하는 기기인 동시 분할한 네트워크를 연결하는 역할도 담당
- 라우터에 의해 분할된 네트워크에는 각각 다른 네트워크 주소가 할당됨
3) 라우터에도 종류가 있다
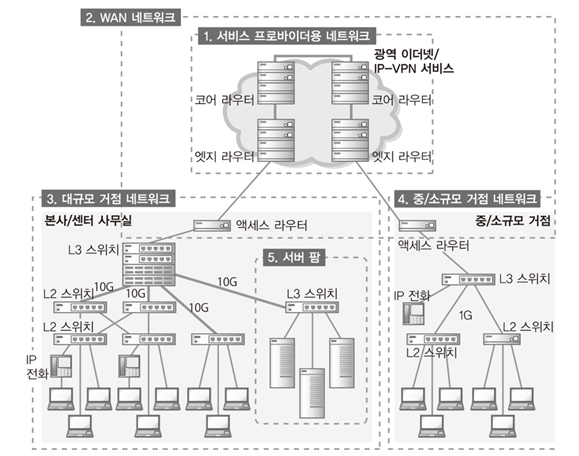
① 서비스 프로바이더용 네트워크
- 대표적인 통신 서비스 : 광역 이더넷, IP-VPN
- 코어 라우터 : 엣지 라우터에서 온 데이터를 통신 사업자망 안에서 중계
- 엣지 라우터 : 통신 사업자망 안과 고객의 구내 네트워크 연결
- 대용량 데이터, 고속 처리 요구, 고사양, 고비용
② WAN 네트워크
- 고객의 거점 간을 연결하기 위한 역할 담당
- 액세스 라우터 (=커스터머 엣지 라우터)
③ 구내에서의 라우터 → 레이어3 스위치
- 대규모 거점 네트워크, 중/소규모 거점 네트워크, 서버 팜에서 사용
④ 그 외의 라우터 종류
- 여러 프로토콜을 사용할 수 있는 멀티 프로토콜 라우터(기업용)
- 액세스 라우터(소규모 거점 네트워크용)
4) 레이어3 스위치와의 차이점
① L3 스위치와의 차이
- 라우터 : 패킷 전송을 소프트웨어적으로 처리 → CPU와 메모리가 연계하여 소프트웨어에 패킷 전송
- L3 스위치 : 패킷 전송을 하드웨어적으로 처리 → ASIC라고 불리는 전용 칩으로 하드웨어 처리 → 빠름
② 라우터는 VPN이나 NAT/NAPT 기능(주소 변환) 지원
- WAN이나 인터넷 연결에 특화된 기능을 가지고 있음
- VPN 기능을 사용하여 안전한 네트워크 실현
- NAT/NAPT 기능을 사용하여 일대다 주소 변환 실현
- PPPoE 기능을 사용하여 인터넷 접속 서비스에 이용 ex) 플렛츠광
5) 라우터를 효과적으로 사용하기 위해서는
① 패킷 필터링
- 네트워크 계층의 데이터 단위인 패킷의 헤더에 들어 있는 정보를 기반으로 필터링 처리 실행 → 간단한 보안 기능
② 이중화
- 중/대규모 거점 네트워크의 경우 라우터의 이중화로 신뢰성을 높이는 것이 가장 중요한 과제
- 이중화 종류
- 여러 대의 라우터가 각각의 WAN 회선을 보유 : WAN 회선은 다른 통신 사업자에서 빌리는 것이 철칙
- 한 대의 라우터로 여러 WAN 회선을 보유 : 신뢰성은 조금 떨어지지만 비용 측면에서 이점
→ WAN 회선 자체에 장애 발생 시 백업 경로의 회선을 통해 통신 가능, but 라우터 자체에 장애 발생 시 모든 통신 불가능
6. 보안 초보 입문
1) 네트워크 보안 접근 방법
① 네트워크 보안
- 보안 전체의 시점
- 무엇을 보호할까? 하드웨어/소프트웨어
- 무엇으로부터 보호할까? 외부로부터/내부로부터
- 네트워크 외부에서의 시점
- 네트워크 내부에서의 시점
2) 무엇으로부터 보호할까? 외부 범행의 대표 예
① 부정 침입 : 각종 업무 서버나 인증 서버, 중계 서버, 리소스(하드디스크, CPU) 등에 허가받지 못한 계정으로 접속하는 것
② 정보 도청 : 도청기를 사용하여 기밀 자료를 빼냄
③ 스푸핑 : 부정으로 얻은 다른 사람의 정보를 이용하여 남용하는 것
④ DoS 공격 : 네트워크나 서버, 호스트 같은 단말로 대량의 데이터를 보내는 행동 → 정상적인 처리 불가능
⑤ 컴퓨터 바이러스 : 데이터나 시스템 자체를 파기하는 악질적인 것도 있음
3) 외부 범행의 대책
→ 외부로부터 액세스하지 못하게 만든다 → DMZ(Demilitarized Zone, 비무장지대)
① 방화벽 : 사내 네트워크와 외부 네트워크의 경계, 접속점으로 데이터의 입출력 제어, DMZ를 만들기 위해 반드시 필요한 기기
- 사내 네트워크 (=신뢰 네트워크)
- 외부 내트워크 (=신뢰할 수 없는 네트워크)
- DMZ
② 방화벽의 주요 기능
- 액세스 제어 (필터링) : 악의적인 부정 액세스로부터 사내 네트워크 보호
- 사내 → 외부 : 사내에서 허락된 애플리케이션 패킷만 통과
- 외부 → 사내 : 사내에서 허가된 애플리케이션으로 사내 네트워크에서 외부 네트워크로 송신되었다가 다시 돌아오는 패킷만 통과
- 외부 → DMZ : 공개 서버의 애플리케이션 패킷만 통과
- DMZ → 외부 : 공개 서버의 애플리케이션에 송신되었다가 다시 돌아오는 패킷만 통과
- 주소 변환 : 사설 주소와 공인 주소를 변환함으로써 사내 IP 주소를 감추는 역할
- 로그 수집 : 부정 액세스에 대한 원인 분석
③ 방화벽의 한계
- 컴퓨터 바이러스 : 방화벽 도입만으로 막을 수 없음
- 바이러스 대비 전용 네트워크 어플라이언스 제품 도입 → 보안 어플라이언스
- 사내 네트워크로부터의 공격 : 방화벽 자신을 경유하지 않는 통신에 대해서는 제어 불가능
4) 무엇으로부터 보호할까? 내부 범행에 대비
→ 외부와 내부의 차이점은 침입할 때 인터넷망을 경유하여 방화벽을 통과하느냐 하지 않느냐의 차이
① 부정 침입 : 부정 단말이 기업 내 LAN에 직접 액세스하고 무단으로 침입
② 정보 도청
③ 스푸핑
④ 정보 유출
⑤ 컴퓨터 바이러스
5) 내부 범행의 대책
① 사용자 인증 : 사용자 ID나 비밀번호를 사용한 인증 방식
- 인증 서버를 통한 인증 : 사용자 정보를 일원 관리하는 인증 서버를 통해 단말 요청 시 저장된 사용자 정보를 이용하여 인증하는 방법
- 네트워크 기기를 통한 인증(로컬 인증) : 네트워크 기기(라우터, 스위치) 자체가 가지고 있는 인증 데이터베이스로 인증하는 방법
② 정보 데이터 암호화 : 중요한 정보를 암호화하고 정보 자체에 액세스 컨트롤하는 것
→ 기밀 정보를 제3자에게 도난당하는 사태를 방지하기 위해 데이터(파일)를 암호화하는 것이 가장 효과적
③ 물리 보안 : 서버룸의 출입 허가를 명확히 하고, 비허가자의 침입을 막아야 함
- 제 1관문 [종합 접수] : 사전 등록 여부 확인 후 등록 정보가 있다면 보안카드를 받아 플랩 게이트로 이동
- 제 2관문 [플랩 게이트] : 건물 내로 들어가기 위해 접수처에서 받은 보안 카드로 인증
- 제 3관문 [카드 리더] : 관내로 들어가기 위해 보안 카드를 출입문 카드 리더에 인증
- 제 4관문 [카드 리더(각 구역)] : 원하는 구역에 들어가기 위해 보안 카드 인증, 서버룸 입실 시 지문 인증, 서버룸은 제한된 인원만 가능,
작업에 필요한 것 이외에는 서버룸에 반입할 수 없음
- 제 5관문 [랙 잠금] : 랙의 자물쇠를 열고 관리하고 있는 기기를 이용해 작업
5) 고도화 네트워크 활용에 대응
① 방화벽에서 UTM으로
- UTM (Unified Threat Management) : 방화벽과 VPN 기능을 기반으로 안티 바이러스, 부정 침입 방지, 웹 콘텐츠 필터링과 같은 여러 보안 기능을 통합하여 일언 관리할 수 있는 장치
- 한 대에 여러 보안 기능을 집약하여 설정이나 관리 작업 단순화
- 도입 간단, 저비용으로 구현 가능
- 한 대에 여러 기능이 집약 → 성능 및 확장성 높음
② 애플리케이션 제어 시대로
- 애플리케이션의 필요와 불필요의 판단은 사용자와 조직에 따라 다름
- 네트워크 상에서 어떤 애플리케이션이 사용되고 있는가?
- 네트워크의 어떤 장소에서 많은 대역이 사용되고 있을까?
- 어떤 나라에서 들어오는 트래픽일까?
- 어떤 애플리케이션을 허가해야 하는가?
③ 차세대 방화벽
- 웹 애플리케이션의 가시화와 제어 가능
- 웹을 허가한 상태에서 같은 포트를 사용하는 웹 애플리케이션의 식별과 제어 가능
④ 차세대 방화벽 특징
- IP 주소뿐만 아니라 사용자나 그룹(조직) 단위로 구별 가능
- 포트 번호나 프로토콜이 아닌 애플리케이션으로 식별 가능
- 애플리케이션과 함께 통과하는 위협이나 중요 데이터를 실시간으로 감지 및 방어 가능
- 애플리케이션의 우선순위 결정 가능
- 사용자의 애플리케이션 이용 상황의 가시화와 액세스 제어 실현 가능
⑤ 차세대 방화벽 동작
- 식별 : 특징 1, 2
- 분류 : 각 기업에서 결정한 보안 정책에 따라 이루어짐
- 제어 : 특징 3, 4, 5
※ 표적형 공격 : 기존에 알려진 공격과는 다른 명확한 목적을 가지고 이루어지는 사이버 공격, 기존의 보안 대책으로는 대응 불가
→ 표적형 공격 대책 보안 어플라이언스
- 탭 모드 : 웹 클라이언트로부터 프록시 서버에 흐르는 웹 통신을 복사해 표적형 공격 대책 보안 어플라이언스로 통신 해석
- 인라인 모드 : 웹 클라이언트로부터 프록시 서버의 사이에 기기를 설치하여 이를 통과하는 웹 통신 감시
7. VoIP 초보 입문
1) VoIP의 기초 지식
①②③④⑤
2) IP 전화의 구성 요소
①②③④⑤
3) VoIP 시그널링 프로토콜
①②③④⑤
4) 음성 품질 기초 지식
①②③④⑤
8. 무선 LAN 초보 입문
1) 무선 LAN이란?
①②③④⑤
2) 무선 LAN의 구조
①②③④⑤
3) 무선 LAN의 보안
①②③④⑤