▶ Colab
- 코드 셀 위에 삽입 : Ctrl + M A
- 코드 셀 아래에 삽입 : Ctrl + M B
- 코드 셀을 마크다운 셀로 : Ctrl + M M
- 마크다운 셀을 코드 셀로 : Ctrl + M Y
- 되돌리기 : Ctrl + M Z
- 셀 삭제 : Ctrl + M D
- 실행 및 출력 : Ctrl/Shift/Alt + Enter
- 전체 셀 실행 : Ctrl + F9
▶ Pandas란?

→ 데이터 분석을 위한 핵심 라이브러리
→ Series와 DataFrame을 활용 → numpy(선형대수)dml 1차원, 2차원 array와 유사
→ array에 index가 있는 형태
▷ Pandas 라이브러리를 활용한 데이터 전처리
위와 같이 new_friend.csv라는 파일이 잘 생성된 것을 확인할 수 있다.
index=False를 해주지 않으면 위와 같이 출력된다.
▶ Series 및 DataFrame
※ 인덱스 사용 이유 : 조회, 데이터 정렬


sort_values() 함수는 시각화할 때 많이 사용
오름차순: ascending=True, 내림차순: ascending=False
단, 변수로 할당해주어야만 다음 값에도 적용됨
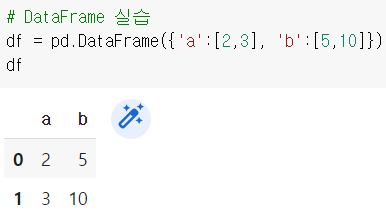
위와 같이 Dataframe을 딕셔너리 형태로 넣을 수 있다.
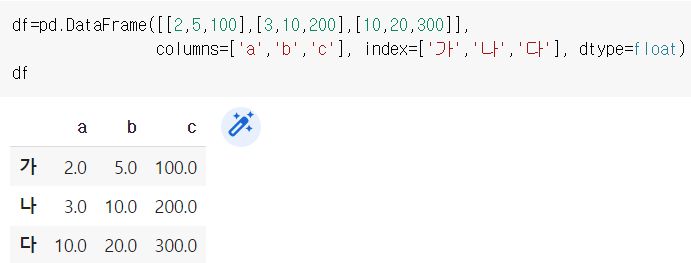
위와 같이 대괄호를 이용하여 DataFrame 생성 시 row 방향으로 데이터가 생성되는 것을 확인할 수 있다.
▶ DataFrame 행, 열 필터링 & 삭제 & 수정

위와 같이 하나의 row만 가져오는 경우 series 형태가 되는 것을 확인할 수 있다.
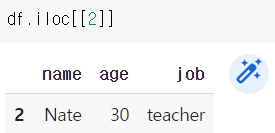
DataFrame 형태로 가져오고 싶다면 위와 같이 대괄호를 하나 더 써주면 된다.

위와 같이 job이라는 행에 해당하는 데이터를 모두 가져올 수 있다.


iloc는 인덱스 기준, loc는 데이터프레임의 형태 그대로를 가져온다.
- iloc는 인덱스와 컬럼을 리스트 배열로 선택하는 것
- loc는 인덱스와 컬럼을 문자로 선택하는 것
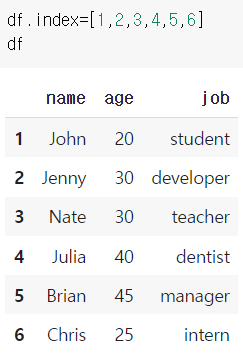

인덱스를 변경한 후 실행한 결과는 위와 같다.
★ 데이터 값이 비어 있는 경우 대체값 처리가 중요하다.
ex) 평균값, 최빈값, 삭제기법, 분포를 확률적으로 랜덤 샘플링→시각화(EDA) 등으로 처리


arange(n) 함수는 0~n-1의 수를 생성해줌, reshape(m,n) 함수는 데이터의 차원을 바꿔줌(m행 n열)
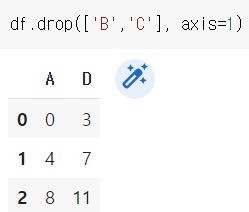
axis=1은 열 삭제, axis=0은 행 삭제, axis의 default 값은 0이다.
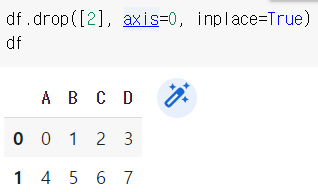
inplace 옵션은 변수 할당 역할을 해준다.
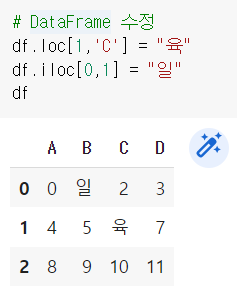
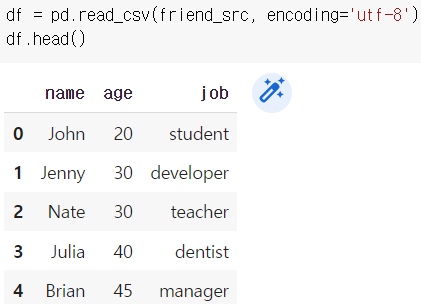
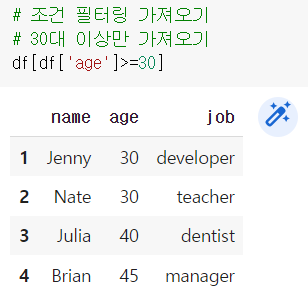
df[]로 한번 더 묶어주기, 안묶어주면 True/False 형태로 출력됨
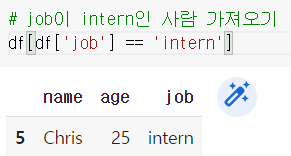
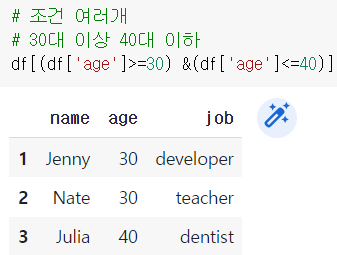
조건 필터링할 때는 괄호를 주의하자!
and : & , or : | → 조건마다 괄호로 묶어주기!
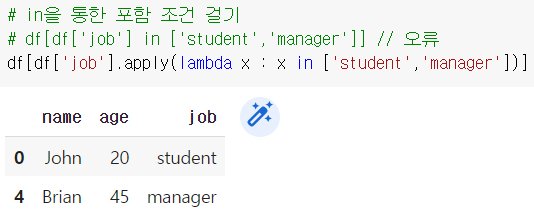
apply() 함수를 통해 위와 같이 포함 조건 필터링을 할 수 있다.
▶ DataFrame 그룹 생성(groupby)
→ pandas의 groupby() 연산자를 사용하여 집단, 그룹별로 데이터 집계 및 요약 가능
→ dataframe을 지정한 그룹으로 나누고, 그룹별로 집계함수를 적용하고, 그룹별 집계 결과를 하나로 합치는 과정
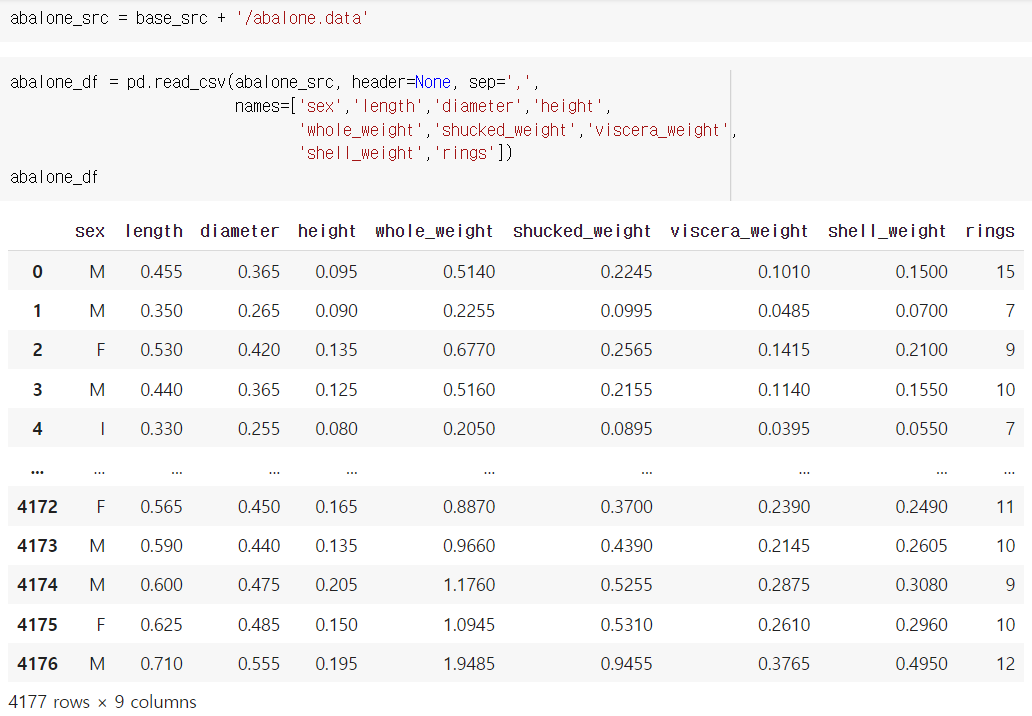
위와 같이 abalone 데이터를 불러올 수 있다.

위와 같이 shape를 통해 row와 columns 수를 확인할 수 있다.

isnull() 함수를 통해 결측값 여부(T/F)를 확인할 수 있고, sum() 함수를 통해 (1/0)을 확인할 수 있다.

한번 더 sum()을 해주면 위와 같이 정확한 개수를 파악할 수 있다.
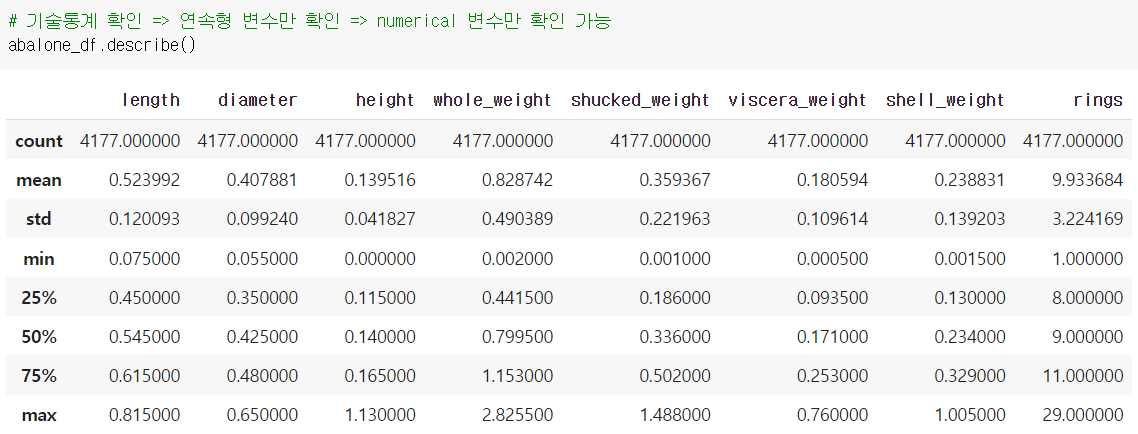
sex와 같은 카테고리컬한 변수는 describe()에서 확인할 수 없다.


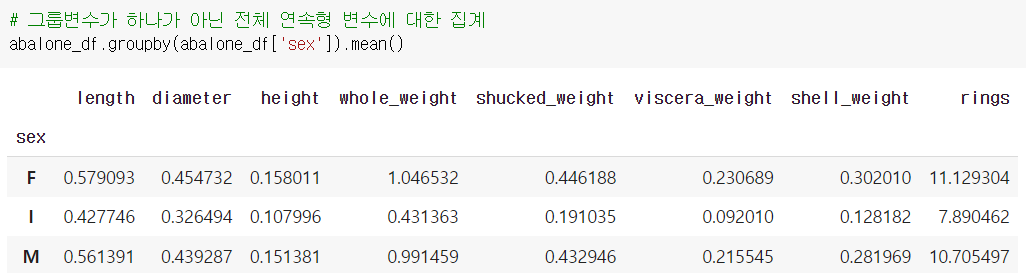
성별을 기준으로 평균집계 groupby를 해준 것이다.
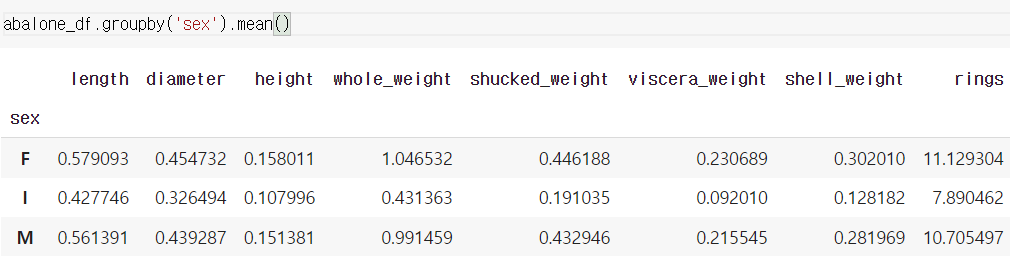
위와 같이 간단하게 표현해도 같은 결과를 확인할 수 있다.
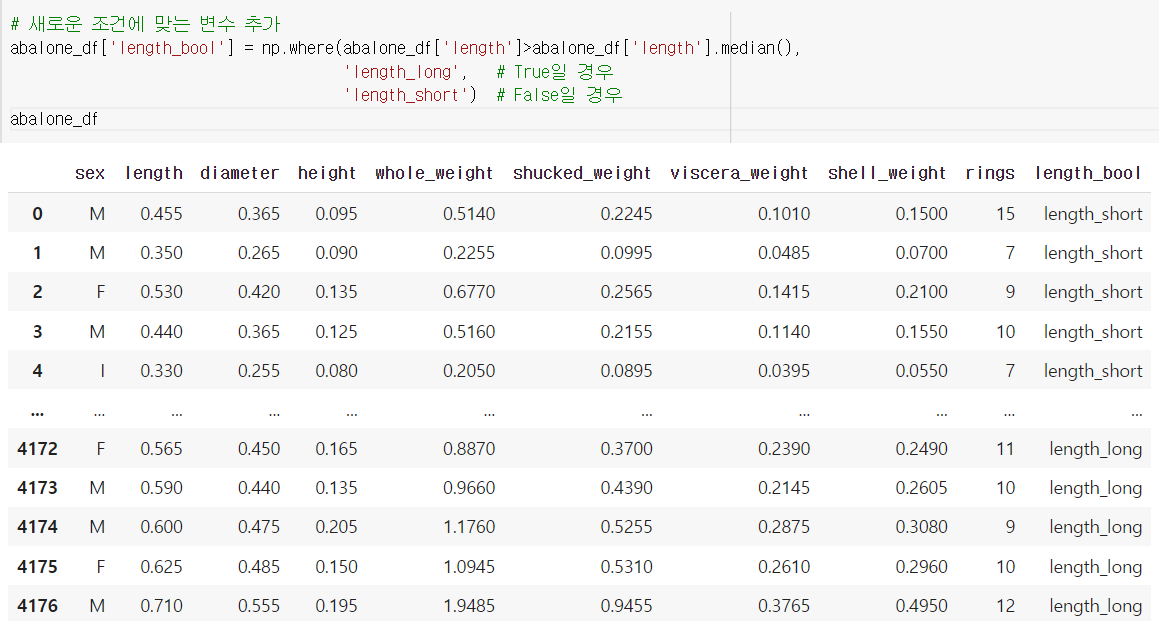
위와 같이 length_bool이라는 새로운 변수가 추가된 것을 확인할 수 있다.
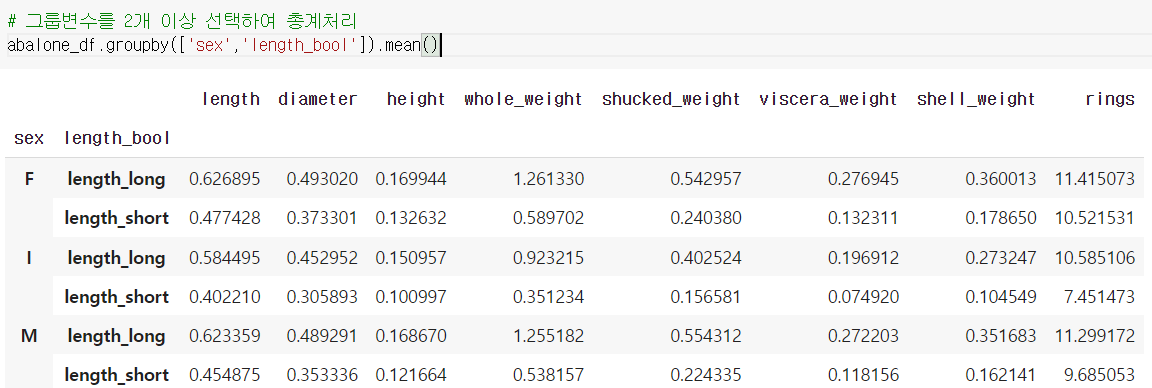
위와 같이 groupby() 활용 가능하다.
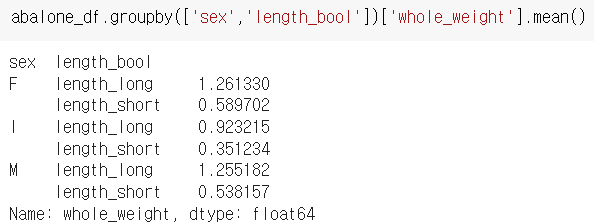
위와 같이 원하는 컬럼의 집계 결과를 출력하도록 하는 것도 가능하다.
▶ DataFrame에서 자주 사용하는 전처리 기법

abalone_df.duplicated().sum()으로 간단하게도 확인 가능
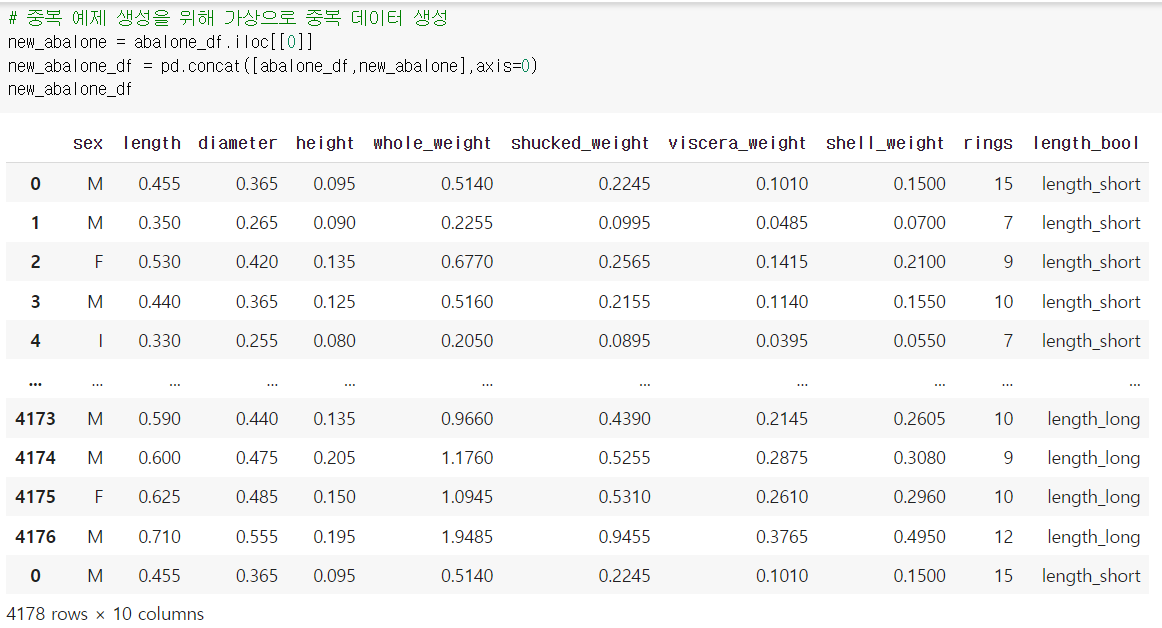
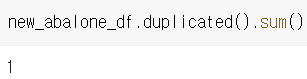
중복데이터 생성 후 duplicated()를 해보면 위와 같은 결과를 확인할 수 있다.

삭제는 drop_duplicates()를 이용
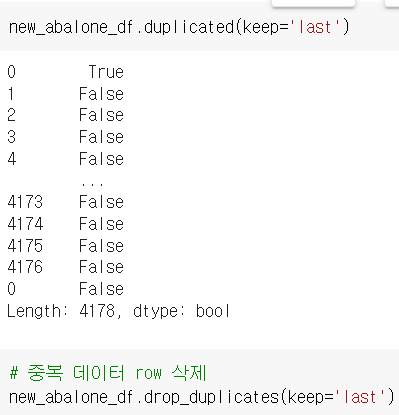
keep='last' 옵션을 사용하여 기존값/추가값 선택 가능
'WINS STUDY > 파이썬 기초 라이브러리부터 쌓아가는 머신러닝' 카테고리의 다른 글
| 섹션 3. 선형 분류 이론 및 실습 (0) | 2022.08.25 |
|---|---|
| 섹션 2. 선형 회귀 이론 및 실습 (0) | 2022.08.13 |
| 섹션 1. Matplotlib & Seabor 라이브러리를 활용한 데이터 시각화 (0) | 2022.08.06 |