1. 매개변수 총 4개를 가지고 실행한다. ( 매개변수명은 자유롭게 가능) 2. 첫번째 매개변수(ex. abcd)는 디렉토리명으로, 사용자 홈디렉토리에 생성한다. (~/) 3. 만든 디렉토리로 이동하여, 매개변수2,3,4 (ex. a, b, c)의 이름의 파일을 생성한다. (touch) 4. 만든 디렉토리에 파일이 잘 생성되었는지 확인하기 위해, ls –l을 해준다. 5. 삭제할 파일을 묻고(read), 입력 받아, 삭제한다. (rm) 6. 삭제 한 후, 다시 ls –l하여 삭제된 것을 확인할 수 있도록 한다.
vi 편집기로 assign0.sh 라는 파일에 위와 같은 내용을 입력해준다.
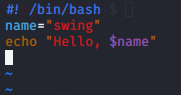
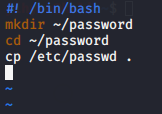
#! /bin/bash를 입력하여 실행할 쉘스크립트를 만들어 준다.
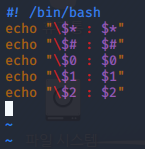
디렉토리를 생성하는 명령어인 mkdir을 이용하여 홈 디렉토리(~)에 $1 디렉토리를 생성해준다. ($1은 매개변수1을 의미)
만들어진 디렉토리로 이동하기 위해 cd ~/$1을 입력해준다.
만들어진 디렉토리에 매개변수 2, 3, 4 파일을 생성하기 위해 touch 명령어를 이용한다. ($2, $3, $4는 매개변수2,3,4를 의미)
만들어진 디렉토리에 파일이 잘 생성되었는지 확인하기 위해 ls -l을 해준다.
삭제할 파일을 묻기 위해 read 명령어를 이용한다. (-p는 입력과 출력을 한 행에서 처리해주는 옵션)
file이라는 변수로 삭제할 파일을 입력받은 후 rm 명령어를 이용하여 입력한 파일을 삭제한다.
입력한 파일이 잘 삭제되었는지 확인하기 이해 다시 ls -l을 해준다.
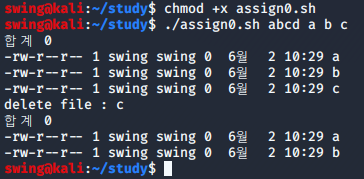
vi 편집기를 저장 후 종료하고, assign0.sh 파일을 실행시키면 다음과 같다.
assign0.sh 라는 파일에 실행 권한을 부여해준 후 abcd라는 디렉토리와 a, b, c라는 파일을 생성한다
위와 같이 처음에는 입력한 파일이 잘 생성된 것을 볼 수 있고 delete file에 삭제할 파일명을 입력하면
배열은 포인터를 사용하여 구현된다. 포인터는 배열을 반복할 때 사용할 수 있다. (배열 인덱스 대신 사용 가능)
C++에서 동적으로 메모리를 할당할 수 있는 유일한 방법이다. (가장 흔한 사용 사례)
데이터를 복사하지 않고도 많은 양의 데이터를 함수에 전달할 수 있다.
함수를 매개 변수로 다른 함수에 전달하는 데 사용할 수 있다.
상속을 다룰 때 다형성을 달성하기 위해 사용한다.
하나의 구조체/클래스 포인터를 다른 구조체/클래스에 두어 체인을 형성하는 데 사용할 수 있다.
▶ 간접 참조 연산자
- 지정된 주소에 있는 값을 액세스하는 연산자
- 역 참조 연산자, 간접 연산자, * 연산자라고도 한다.
- 피연산자의 메모리에 접근하여 주소 값을 저장해가는 변수
- ex) a의 주소를 100번지를 가리킨다고 가정하자.
int a = 200; int* p; p = &a;
cout << p; // 이 경우 a의 주소값인 100이 출력됨 cout << *p; // 이 경우 a의 값인 200이 출력됨
위의 표처럼 포인터 변수 앞에 '*' 을 붙여주어야 값이 출력된다.
▶ 포인터 연산
- 포인터 연산 규칙
① 포인터끼리 더할 수 없다. ( 주소 값을 더하는 것은 쓸모가 없음 )
② 포인터끼리 뺄 수 있다. ( 주소 값의 거리를 구함으로써 메모리상에서 얼마나 떨어져 있는지 구해낼 수 있음 )
③ 포인터에 정수를 더하거나 뺄 수 있다.
④ 자료형 포인터의 값을 1 증가시키면 자료형의 크기만큼 증가된다.
⑤ 포인터끼리 대입은 가능하다. ( 단, 대입받을 포인터와 대입할 포인터의 타입이 일치해야함 )
⑥ 포인터에 정수를 대입할 수 없다.
⑦ 포인터와 실수와의 연산은 할 수 없다.
⑧ 포인터끼리 비교는 가능하다.
- 포인터 증감 연산
※ 증감 연산자(++, --)와 참조 연산자(*)는 함께 쓰일 수 있다.
a = *ptr++
a에 ptr의 값을 대입한 후 ptr 증가 (주소가 증가)
a = (*ptr)++
a에 ptr의 값을 대입한 후 *ptr 증가 (값이 증가)
a = *++ptr
ptr 증가한 후 a에 대입 (주소가 증가, 증가한 주소가 가리키는 값 대입)
a = ++*ptr
*ptr 증가한 후 a에 대입 (값의 증가, 증가한 값 대입)
- ex) a의 주소는 100번지, b의 주소는 200번지라고 가정하자.
int b = 10; int* ptr = &b; int a;
cout << ptr; // b의 주소값인 200이 출력됨 cout << *ptr; // b의 값인 10이 출력됨
a = *ptr++;
cout << a; // 값을 대입 후 ptr이 증가하므로 10이 출력됨 cout << ptr; // b의 주소에서 4바이트 증가한 204가 출력됨 cout << *ptr; // a의 주소값인 100이 출력됨
int b = 10; int* ptr = &b; int a;
cout << ptr; // b의 주소값인 200이 출력됨 cout << *ptr; // b의 값인 10이 출력됨
a = (*ptr)++;
cout << a; // 값을 대입 후 ptr이 증가하므로 10이 출력됨 cout << ptr; // ptr은 증가하지 않으므로 200이 출력됨 cout << *ptr; // ptr의 값이 증가하므로 11이 출력됨
int b = 10; int* ptr = &b; int a;
cout << ptr; // b의 주소값인 200이 출력됨 cout << *ptr; // b의 값인 10이 출력됨
a = *++ptr;
cout << a; // ptr을 증가시킨 후 대입하므로 a의 주소값인 100이 출력됨 cout << ptr; // b의 주소에서 4바이트 증가한 204가 출력됨 cout << *ptr; // a의 주소값인 100이 출력됨
int b = 10; int* ptr = &b; int a;
cout << ptr; // b의 주소값인 200이 출력됨 cout << *ptr; // b의 값인 10이 출력됨
a = ++*ptr;
cout << a; // ptr의 값을 증가시킨 후 대입하므로 a의 값인 11이 출력됨 cout << ptr; // ptr은 증가하지 않으므로 200이 출력됨 cout << *ptr; // ptr의 값이 증가하므로 11이 출력됨
▶ 포인터와 배열
- 포인터와 배열은 매우 긴밀한 관게를 갖고 있고, 어떤 부분에서는 서로를 대체할 수도 있다.
- 배열의 이름은 포인터 상수이다.
※ 포인터 상수란 포인터 변수가 가리키고 있는 주소 값을 변경할 수 없는 포인터를 의미
- 가변 문자열 길이를 저장할 때는 배열보다 포인터가 유용하다.
- 정수형 배열의 메모리 할당
ex) int aa[3] = {10, 20, 30};
- 배열의 주소 표현 • aa[0]의 주소(&aa[0]) = 1031번지 • aa[1]의 주소(&aa[1]) = 1035번지 • aa[2]의 주소(&aa[2]) = 1039번지 • 배열 이름 aa = 전체 배열의 주소 = 1031번지 • 배열 aa의 주소를 구할 때는 ‘&’를 쓰지 않고, 단순히 ‘aa’로 표현
- 배열 이름 활용법
ex) aa 값을 1031로 가정하고, aa+1을 계산한 결과는? • 예상결과 : aa+1 ➔ 1031 + 1 = 1032 (X) • 실제 결과: aa+1 ➔ 1031 + 4 = 1035 (O)
계산 과정) ‘+1’의 의미 : 배열 aa의 위치에서 한칸 건너뛰어라 한칸 : aa가 정수형 배열이므로 4byte 즉, aa+1 = &aa[1] = 1035
1. 루트 디렉토리, /home 디렉토리, 사용자 홈 디렉토리(~) 의 아이노드 번호와 링크 수 확인
※ 모든 디렉토리는 항상 두 개의 항목( 자기자신(.) , 부모 디렉토리(..) )을 가지고 있다.
※ 모든 디렉토리의 기본적인 링크수는 2이다.
※ ls -ali라는 명령어를 이용하여 다음 그림과 같이 모든 파일의 상세 정보와 아이노드 번호를 출력하고,
아이노드 번호와 링크 수를 확인한다.
- 루트 디렉토리
- /home 디렉토리
- 사용자 홈 디렉토리(~)
2. 사용자 홈 디렉토리(~)에 week3 디렉토리 생성
mkdir을 이용하여 week3 디렉토리를 생성한다.
stat을 이용하여 파일의 메타 정보를 출력한다.
※ stat[파일명] → 크기, 파일타입, 장치, 하드링크수, 접근권한, 소유자, 그룹, 접근시간, 수정시간 등을 알 수 있다.
3. week3 디렉토리에 test.txt 파일 생성
touch로 test.txt라는 파일을 생성한다
ls명령어를 이용하여 파일 목록을 확인할 수 있고 현재 test.txt 파일의 하드링크 수는 1개임을 확인할 수 있다.
4. week3 디렉토리에 test.txt 파일의 하드 링크 파일 hd.test 파일 생성
ln 원본파일명 하드링크파일명 → test.txt 파일의 하드 링크 파일 hd.test 파일을 생성한다.
hd.test와 test.txt의 아이노드 번호는 같고 하드링크 수는 1 증가하여 2개임을 확인할 수 있다.
※ 원본 파일과 하드링크 파일은 같은 아이노드 번호를 공유한다.
vi 편집기로 hd.test파일에 hello world를 입력한 후 cat을 이용하여 파일 내용을 출력해보면 test.txt와 hd.test 둘 다 동일한 내용이 출력되는 것을 볼 수 있다.
위와 같이 aa와 bb파일을 생성했을 때 하드링크 수가 증가하는 것을 확인할 수 있다.
vi 편집기로 hd.test의 내용을 hello swing으로 편집한 후 test.txt의 파일 내용을 출력하면 hello swing이 출력되는 것을 확인할 수 있다. 또한 test.txt 파일을 삭제한 후 hd.test의 파일 내용을 출력했을때, 출력이 가능함을 확인할 수 있다.
5. week3 디렉토리에 test.txt 파일의 심볼릭 링크 파일 ls.test 파일 생성
ln -s 원본파일명 심볼릭링크파일명 → test.txt 파일의 심볼릭 링크 파일 ls.test 파일을 생성한다.
심볼릭 링크 파일이 파란색 글씨로 생성된 것을 볼 수 있고 원본 파일과 심볼릭링크 파일의 아이노드 번호가 다르다는 것을 확인할 수 있다.
test.txt 파일을 삭제했을 때 아무런 문제가 나타나지 않던 하드링크와 다르게 심볼릭 링크는 ls.test 파일의 글씨가 빨간색으로 바뀐 것을 볼 수 있고 ls.test 파일의 내용을 출력하지 못하는 것을 확인할 수 있다.
파일 시스템의 논리적 구조 작성하기
1. 루트 디렉토리, /home 디렉토리, 사용자 홈 디렉토리(~) 의 아이노드 번호와 링크 수 확인
- 루트(/) 디렉토리
루트 디렉토리 이외에 아무것도 없다면 위와 같은 그림을 그릴 수 있다.
stat 명령어를 이용하여 루트 디렉토리의 아이노드 번호와 링크 수를 확인할 수 있다.
이를 이용하여 루트 디렉토리의 논리적 구조를 그리면 다음 그림과 같다.
- /home 디렉토리
stat 명령어를 이용하여 홈 디렉토리의 아이노드 번호와 링크 수를 확인할 수 있다.
이를 이용하여 홈 디렉토리의 논리적 구조를 그리면 다음 그림과 같다.
- 사용자 home 디렉토리 (~)
stat 명령어를 이용하여 사용자 홈 디렉토리의 아이노드 번호와 링크 수를 확인할 수 있다.
이를 이용하여 사용자 홈 디렉토리의 논리적 구조를 그리면 다음 그림과 같다.
2. 사용자 홈 디렉토리(~)에 week3 디렉토리 생성
stat 명령어를 이용하여 사용자 홈 디렉토리에 생성한 week3 디렉토리의 아이노드 번호와 링크 수를 확인할 수 있다.
위의 그림과 같이 사용자 홈 디렉토리 엔트리에 week3 디렉토리가 추가된다.
week3 디렉토리의 아이노드 블록과 데이터 블록이 생성되고 week3 디렉토리 아이노드의 포인터는 week3의 데이터 블록을 가리킨다.
3. week3 디렉토리에 test.txt 파일 생성
week3 디렉토리에 test.txt 파일을 생성하면 week3디렉토리 엔트리에 test.txt가 추가된다.
이 때, test.txt 파일의 내용은 Hello world이다.
4. week3 디렉토리에 test.txt 파일의 하드 링크 파일 hd.test 파일 생성
week3 디렉토리에 하드링크 파일 hd.test 파일을 생성하면 week3 디렉토리 엔트리에 hd.test 파일이 추가된다.
이 때, 하드링크 파일 hd.test와 원본 파일 test.txt의 아이노드 번호는 동일하다.
또한, 하드링크 파일이 추가되었기 때문에 원본 파일의 링크 수가 증가한다.
5. week3 디렉토리에 test.txt 파일의 심볼릭 링크 파일 ls.test 파일 생성
week3 디렉토리에 심볼릭링크 파일 ls.test 파일을 생성하면 week3 디렉토리 엔트리에 ls.test 파일이 추가된다.
이 때, 소프트 링크 파일의 아이노드가 생성되고 소프트 링크 파일의 데이터 블록에 원본 파일의 경로가 저장된다.
→ 파일 시스템 크기, 블록 수, 이용 가능한 빈 블록 목록 → 빈 블록 목록에서 그 다음 빈 블록을 가리키는 인덱스 → inode 목록 크기, 파일 시스템에서 빈 inode 수와 목록 → 빈 inode 목록에서 그 다음 빈 inode 수와 목록 → 빈 블록과 빈 inode 목록들에 대한 록 필드 → 슈퍼 블록들이 수정되었는지에 대한 플래그 → 파일 시스템 이름 및 디스크 이름
③ 아이노드 블록 ( inode)
- inode들을 모아놓은 곳; 한 블록에 여러 개의 inode를 저장하고 있다.
- 파일이나 디렉토리에 대한 모든 정보를 가지고 있는 구조체
- 파일 하나당 하나의 아이노드가 사용되며 여러 파일의 참조(link)가 가능하다.
- 파일을 처리할 때 파일 이름이 아닌 아이노드 번호를 이용한다.
- 아이노드가 소유한 정보
→ 파일크기 → 생성시간, 사용시간, 변경시간 → 접근권한 → 사용자 ID, 그룹 ID → 파일 링크 수 → 데이터 블록 주소
- 아이노드의 기능
1.파일을 생성하면 inode가 "아이노드 리스트"에 만들어지고 inode-Number 및 파일 이름, 디렉토리가 등록됨. 2.파일을 삭제하면 inode 파일 링크 수가 하나 감소되고 해당 파일의 inode-Number는 0으로 바뀜. 3.원본 파일을 하드 링크하면 동일한 inode-Number임.