1. 파이썬 개념 정리 & 예시
- github.com/jihyun28/Python/blob/main/practice.py
jihyun28/Python
Contribute to jihyun28/Python development by creating an account on GitHub.
github.com
[무료] 파이썬 무료 강의 (기본편) - 6시간 뒤면 나도 개발자 - 인프런 | 강의
6시간. 여러분이 파이썬 개발자가 되는데 필요한 시간입니다. 핵심 내용만 선정 / 챕터마다 퀴즈 & 해설 / 실생활 기반 예제로 아주 쉽게 설명합니다. 그리고 완전 무료입니다., ★나도코딩님의
www.inflearn.com
2. 파이썬으로 웹 스크래핑하기
### 웹스크래핑과 웹크롤링
# 웹 크롤링 : 웹페이지 내에서 허용된 링크를 따라가면서 마구잡이로 데이터를 가져오는 것
ex) 서점이벤트
# 웹 스크래핑 : 웹페이지 내에서 필요한 부분만 가져오는 것
ex) 종이 한 장에 시험내용 정리
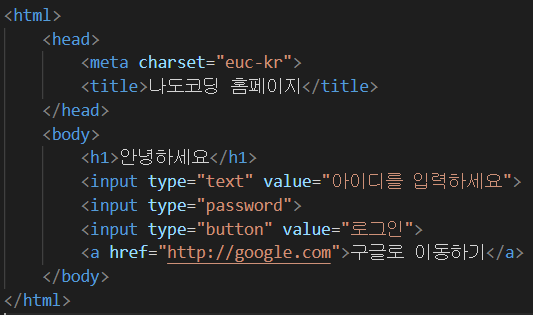
### HTML
※ html 공부 사이트 : w3school
### XPath
# 비슷한 태그나 요소가 있을 때 어떤 것을 지정한 것을 명확하게 하기 위해서 xpath를 사용
# xpath 구성
/학교/학년/반/학생[2]
//*[@학번="1-1-2] -> 밑의 그림과 같은 코드를 간소화 가능
/html/body/div/div/div/div/div/div/span/a...
//*[@id="login"]

### 크롬
개발자도구 : [F12]
원하는부분 오른쪽 마우스 > Copy > Copy xpath
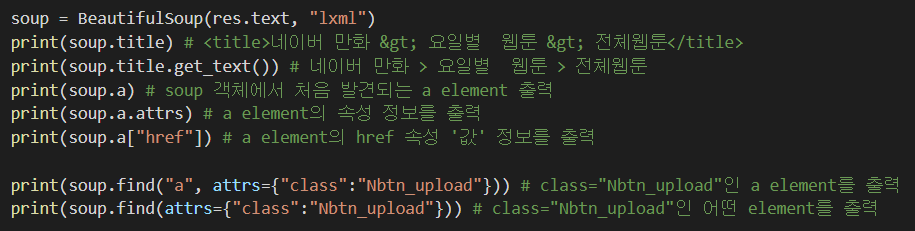
### Requests
#html 문서 정보를 가져오기 위해 사용하는 라이브러리


위와 같이 mynaver.html이라는 파일이 생성되고, 길이가 출력된 것으로 보아 웹 스크래핑이 잘 진행된 것을 확인할 수 있다.
### 정규식
※ 정규식 공부 사이트 : w3school, python re
# . : 하나의 문자를 의미 ex) ca.e -> care, cafe (O) | caffe (X)
# ^ : 문자열의 시작 ex) ^de -> desk, destination (O) | fade (X)
# $ : 문자열의 끝 ex) se$ -> case, base (O) | face (X)
print(m.group()) # 일치하는 문자열 반환
print(m.string()) # 입력받은 문자열
print(m.start()) # 일치하는 문자열의 시작 index
print(m.end()) # 일치하는 문자열의 끝 index
print(m.span()) # 일치하는 문자열의 시작과 끝 index
# 1. p = re.compile("원하는 형태")
# 2. m = p.match("비교할 문자열") : 주어진 문자열의 처음부터 일치하는지 확인
# 3. m = p.search("비교할 문자열") : 주어진 문자열 중에 일치하는 것이 있는지 확인
# 4. lst = p.findall("비교할 문자열") : 일치하는 모든 것을 "리스트" 형태로 반환
### User Agent
#user agent 확인
https://www.whatismybrowser.com/detect/what-is-my-user-agent
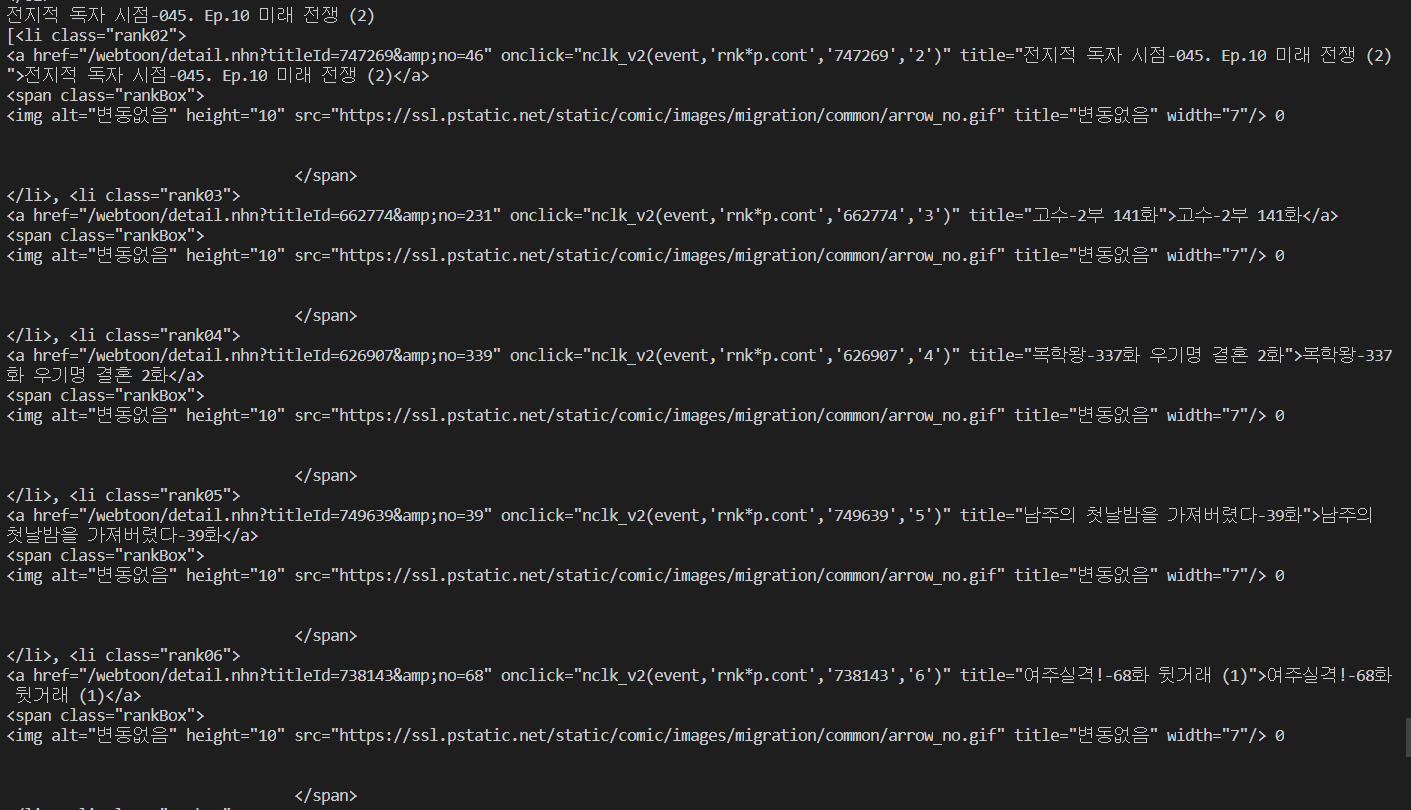
### 네이버 웹툰 스크래핑



위의 코드를 실행한 결과는 다음과 같다.


위의 코드를 실행한 결과는 다음과 같다.


위의 코드를 실행한 결과는 다음과 같다.



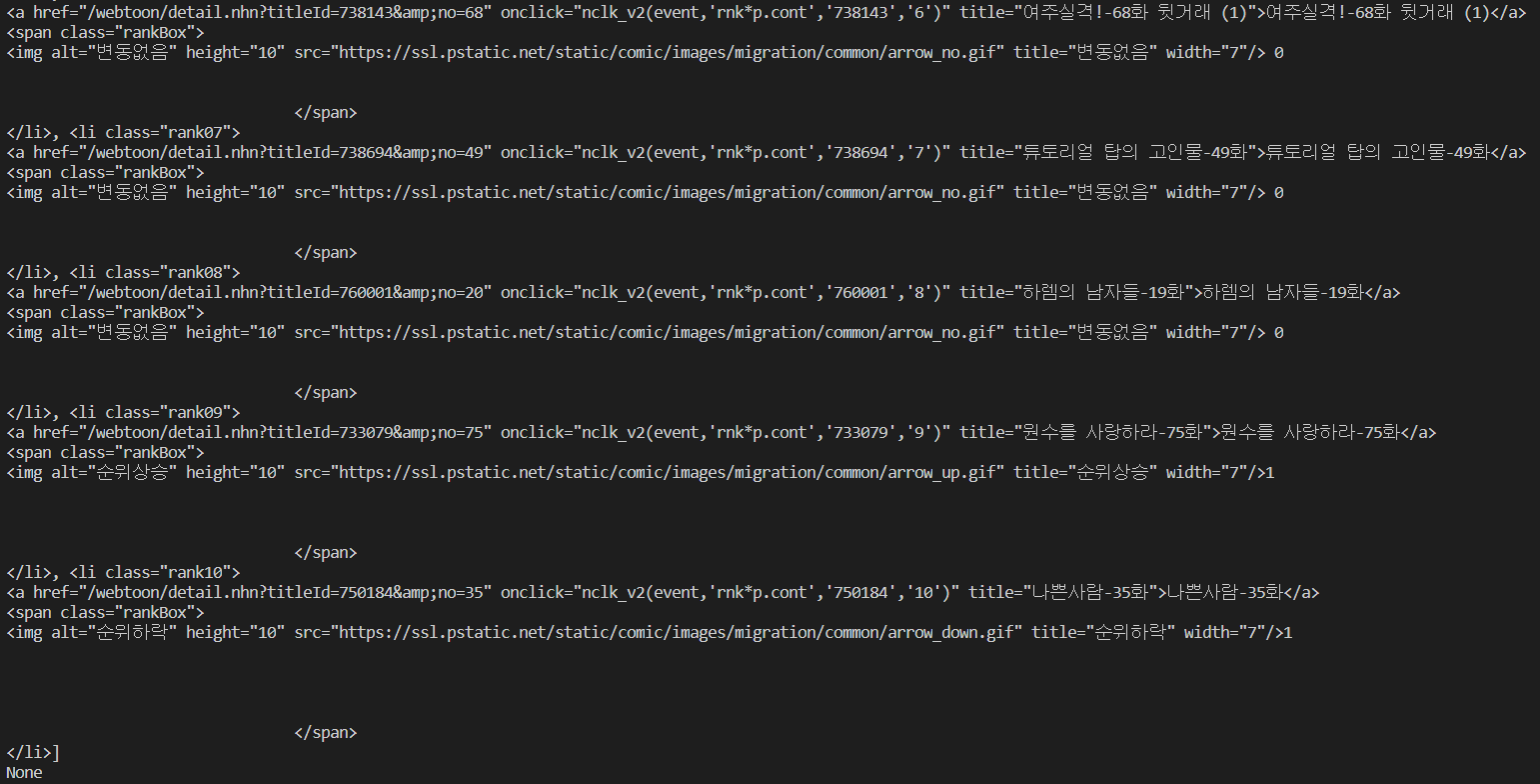

위의 코드를 실행한 결과는 다음과 같다.



[무료] 파이썬 무료 강의 (활용편3) - 웹 스크래핑 (5시간) - 인프런 | 강의
HTML 기초부터 고수들의 스크래핑 비법까지, 모두 알려드리겠습니다. 이 영상 하나면 충분합니다., 재미있고 유용한 웹 스크래핑, 각종 데이터를 내 손으로 다루고 얻어보세요! 혹시 늑대와 일곱
www.inflearn.com
'2021-1 STUDY > Web Programming Study' 카테고리의 다른 글
| scant3r_SQLI (0) | 2021.05.05 |
|---|---|
| scant3r_SSTI (0) | 2021.05.05 |
| Web Scanner (0) | 2021.04.11 |